继续看P,对于p来说,p的生命周期比较简单,在进程刚初始化时,便会首先初始化所有的p:
P的初始化
在系统入口函数runtime·rt0_go(SB)中,会调用schedinit()函数初始化全局变量sched时,会调用procresize()初始化对应数量的p:
func procresize(nprocs int32) *p {
//...
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
//初始化p
//设置p的状态为_Pgcstop
//初始化p的各种缓存
pp.init(i)
//将p保存到全局数组中
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
_g_ := getg()
//...
var runnablePs *p
for i := nprocs - 1; i >= 0; i-- {
p := allp[i]
if _g_.m.p.ptr() == p {
continue
}
//设置p的状态为_Pidle
p.status = _Pidle
//如果当前的p的本地队列中没有g
if runqempty(p) {
//则将其放入全局idle p队列中
pidleput(p)
} else {
//否则,如果p中含有需要运行的g
//则尝试获取一个空闲的m与p绑定
p.m.set(mget())
p.link.set(runnablePs)
runnablePs = p
}
}
//重新初始化窃取队列的顺序
stealOrder.reset(uint32(nprocs))
var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32
atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs))
return runnablePs
}
由于涉及到部分通过runtime.GOMAXPROCS()动态调整p的数量,因此代码中包含一些动态调整数量的代码,这里我们仅看初始化即可。
这里可以看到procresize()主要是初始化了gomaxprocs数量的p,然后将其放入全局idlep队列中,一般来说p在初始化完毕之后,除非再次调用procsize()调整p的数量,否则p不会被销毁。
P的运行
在GMP模型中,m必须绑定p才能运行,p也必须依赖m也能调度p中的g,因此每当存在空闲的m被唤醒或新m的创建时,m会通过调用acquirep()尝试从全局idelp中获取一个空闲的p进行绑定。
例如:当调用newproc()创建一个新的goroutine时,goroutine创建完毕后会尝试唤醒一个空闲的m:
//runtime.proc.go
func wakep() {
//如果空闲的p数量为0,则直接返回
if atomic.Load(&sched.npidle) == 0 {
return
}
//
if atomic.Load(&sched.nmspinning) != 0 || !atomic.Cas(&sched.nmspinning, 0, 1) {
return
}
//唤醒m
startm(nil, true)
}
由于m需要首先绑定p才允许运行,因此在唤醒m前,会首先从pidle队列中尝试获取空闲的p,如果获取失败,则返回;否则,将p与m绑定并运行。
//runtime.proc.go
func startm(_p_ *p, spinning bool) {
mp := acquirem()
lock(&sched.lock)
if _p_ == nil {
//尝试从空闲的p列表中获取一个p
_p_ = pidleget()
//获取失败,则返回,因为m必须绑定p才能运行
if _p_ == nil {
unlock(&sched.lock)
if spinning {
// The caller incremented nmspinning, but there are no idle Ps,
// so it's okay to just undo the increment and give up.
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("startm: negative nmspinning")
}
}
releasem(mp)
return
}
//....
//设置nextp属性为p,暂存p
nmp.nextp.set(_p_)
//唤醒m
notewakeup(&nmp.park)
}
当成功唤醒m后,m会调用acquirep(_g_.m.nextp.ptr())函数绑定p:
//runtime#proc.go
func acquirep(_p_ *p) {
//连接p
wirep(_p_)
_p_.mcache.prepareForSweep()
if trace.enabled {
traceProcStart()
}
}
//runtime#proc.go
func wirep(_p_ *p) {
//获取当前的g
_g_ := getg()
//如果m已经绑定p,则报错
if _g_.m.p != 0 {
throw("wirep: already in go")
}
//检查p的状态
if _p_.m != 0 || _p_.status != _Pidle {
id := int64(0)
if _p_.m != 0 {
id = _p_.m.ptr().id
}
print("wirep: p->m=", _p_.m, "(", id, ") p->status=", _p_.status, "\n")
throw("wirep: invalid p state")
}
//p与m互相绑定
_g_.m.p.set(_p_)
_p_.m.set(_g_.m)
//设置的p的状态为running
_p_.status = _Prunning
}
可以看出来,p相当于m的quota,每当创建goroutine的时候,都会检查当前时候有多余的p可以绑定,如果有,则尝试唤醒或创建m与获取的p绑定并运行。p通过m的绑定,将状态从pidle转换为prunning
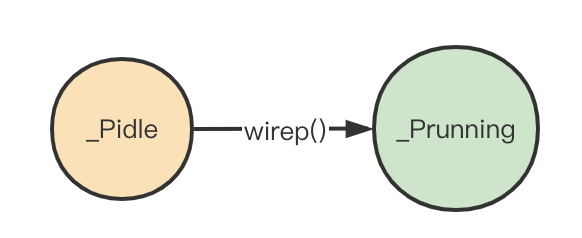
P与系统调用
在前面解析当g执行系统调用的时候,由于系统调用会阻塞m,因此g首先会将p与m解绑,然后通过m执行系统调用,此时p陷入_Psyscall状态,状态流程图如下:
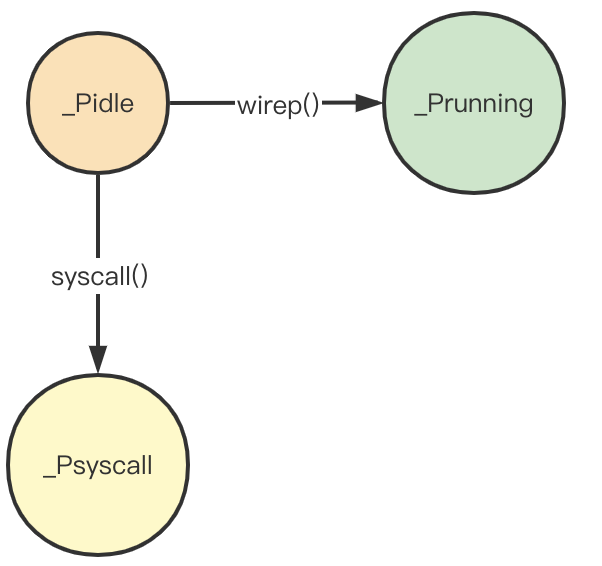
对于一个处于_Psyscall状态的p,存在两种情况:
- 等待
syscall返回,此时g会检查之前绑定的p的状态,如果依然为_Psyscall,那么刚好可以再次绑定继续运行。 syscall调用时间过长,此时sysmon()函数会轮询所有的p,如果存在一个p处于_Psyscall时间过长,则sysmon()会尝试新建一个m与来与之绑定并运行。
在sysmon()中,会调用retak()函数执行以上:
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
if _p_ == nil {
continue
}
pd := &_p_.sysmontick
s := _p_.status
sysretake := false
//检查运行时间,如果运行时间过长则实施抢占
if s == _Prunning || s == _Psyscall {
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(_p_)
sysretake = true
}
}
//如果是系统调用状态
if s == _Psyscall {
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
t := int64(_p_.syscalltick)
if !sysretake && int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
//满足以下3个中的任意一个条件都允许创建一个新的m来接管p
//1. 当前p还存在剩余的g的需要调度
//2. 没有处于spnning状态的m 并且 没有空闲的p
//3. 距离执行syscall的时间已经超过10ms
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
unlock(&allpLock)
incidlelocked(-1)
//修改p的状态
if atomic.Cas(&_p_.status, s, _Pidle) {
if trace.enabled {
traceGoSysBlock(_p_)
traceProcStop(_p_)
}
n++
_p_.syscalltick++
//创建或唤醒新的m,绑定p继续运行
handoffp(_p_)
}
incidlelocked(1)
lock(&allpLock)
}
}
unlock(&allpLock)
return uint32(n)
}
可以看到retake()函数主要是检查检查p进入_Psyscall状态的时间,如果满足3个条件中的任意一个,则会尝试唤醒一个新的m来绑定p,使其继续运行。从这里也可以看到,对于g进入系统调用时,如果调用时间比较短,则不会切换m,如果调用时间过长,则p会重新绑定一个新的m继续运行,避免阻塞过长时间。
这里也可以看到一个问题:如果由于
sysmon()一般是10ms运行一次,而syscall超时检测需要至少2个周期。也就是说如果存在一个系统调用超过20ms没有返回,则golang可能会创建一个新的m来绑定p,如果这种系统调用足够频繁的话,那么m的数量也会越来越多。
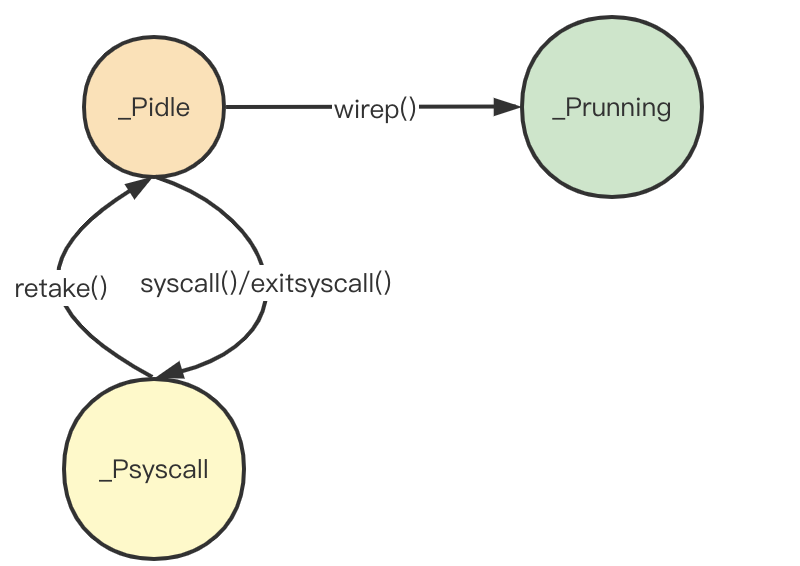
P的退出
由于p的数量是可以动态调整,因此当新的p的数量低于之前p的数量时,多余的p则会进入destroy()方法,destroy()方法会清理属于p的各个属性,比如timer、mcache、sudogcache等,最后会将p的状态设置为_Pdead
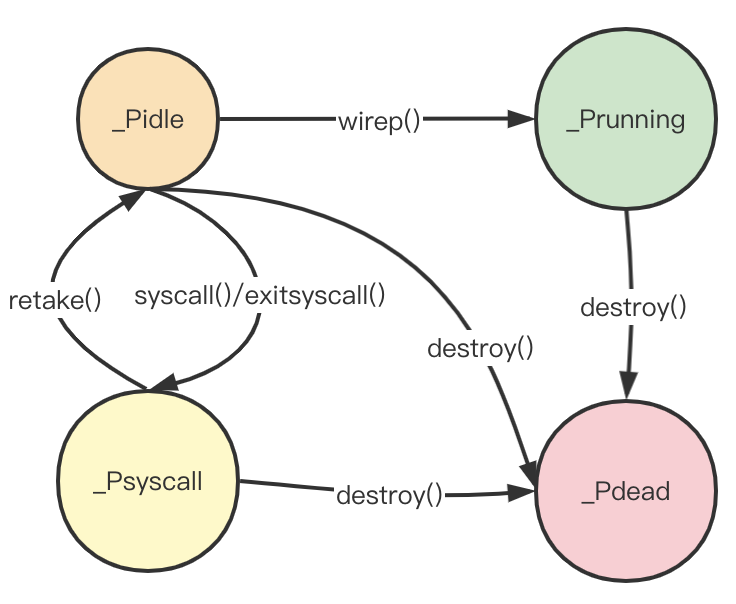
至此,p的状态补充完毕。从p的状态图可以看出来,对于p来说:
p在系统启动时,就已经初始化完毕,所有的p都会进入_Pidle状态等待m的绑定。- 当存在
m被唤醒或者创建时,m会尝试从pidle队列中获取空闲的p,如果获取成功,p进入_Prunning状态。 - 当与
p绑定的m执行到系统调用时,m在执行系统调用前,m会先与p解绑,p此时会进入_Psyscall状态,此时p会在两种情况恢复:- 进入系统调用的
m短时间恢复,此时m会再次绑定p继续运行。 - 或者:
m由于长时间阻塞在系统调用,此时后台守护进程sysmon()会检测到当前p系统调用时间过长,sysmon()会尝试唤醒一个m或者创建一个新的m接管p继续运行。
- 进入系统调用的
- 最后,当系统执行
procsize()调整p数量时,多余的p会通过destroy()方法进入_Pdead状态,最后退出。