在前面的文章中,我们分析到Mutex在休眠g和唤醒g分别用到了runtime_SemacquireMutex和runtime_Semrelease,接下来简单分析这两个函数的源码。
SemacquireMutex其源码对应runtime#sema.go文件中的semacquire1()方法,runtime_Semrelease对应semrelease1(),在分析其源码之前,我们简单描述其功能:
semacquire1一般需要和semrelease1配套使用,其主要作用是对信号量sema的抽象,其主要作用对象是传入的参数addr,semacquire1负责获取信号量,调用semacquire1方法会尝试对参数addr指向的变量减一,如果信号量不够则休眠直到被唤醒;semrelease1负责释放信号量,调用semrelease1会对参数addr指向的变量加一,同时尝试唤醒等待的g-
semacquire在发现信号量不够时会通过sudog结构体保存当前g信息,并将sudog保存在semaTable数组中,在之后调用gopark()休眠。semrelease则是通过查找semaTable来判断当前addr是否有等待的g,如果有,则调用goready()唤醒。 -
sudog有个全局缓存池sudogcache,其每个p维护一个sudogcache,当p维护的sudogcache不够时,会再去全局sudogcache中获取,如果全局sudogcache中数量依然不够,才会通过new分配。也就是这是一个二级缓存。 -
semaTable数组作为一个全局变量,所有休眠的g信息都保存在这个semaTable中,semaTable原理类似HashMap,其固定大小为251,Hash方法为将addr的值右移3位再除以251,sudog为value。所有hash到同一个槽的value则再通过Treap数据结构保存。每个Treap节点又是一个链表,表示等待这个信号量的所有结构体。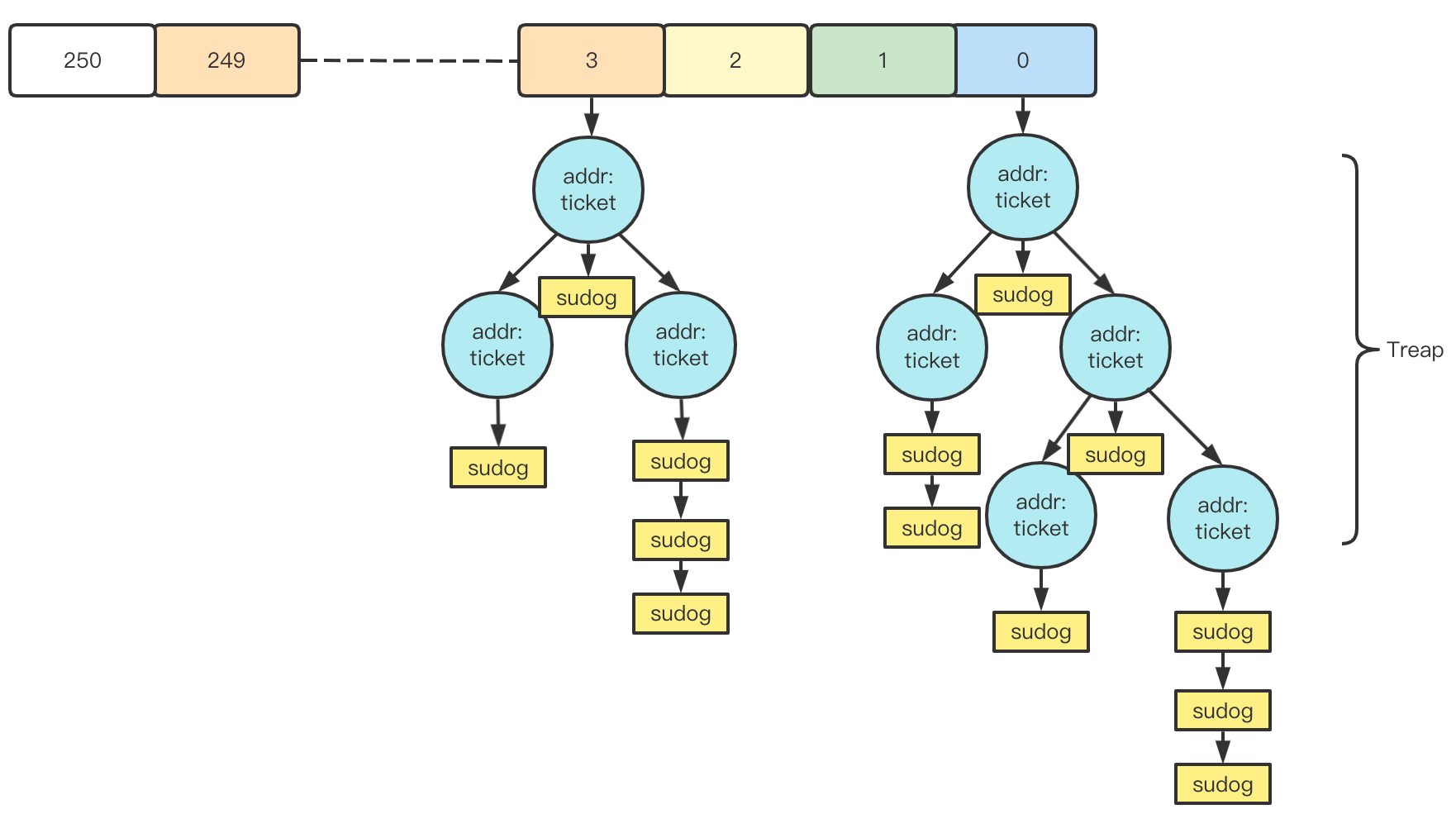
这里
Treap的解决方案和Java的HashMap差不多,不过Java的HashMap是通过红黑树解决,本质都是为了更快的查找。关于
Treap的原理这里不再赘述,只用知道其查找和删除的时间复杂度都为O(logn),Treap的特点是实现简单,但是性能相比红黑树稍差。
接下来分析源码。
semacquire
func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags, skipframes int) {
//获取当前运行的g
gp := getg()
if gp != gp.m.curg {
throw("semacquire not on the G stack")
}
//fast path
//检查addr指向的value是否大于0
//如果大于0则尝试减一,如果成功则直接返回
if cansemacquire(addr) {
return
}
//到这里说明获取信号量失败,开始准备休眠
//获取缓存的sudog对象
s := acquireSudog()
//获取addr hash后对应的Treap的根节点
root := semroot(addr)
//初始化属性
t0 := int64(0)
s.releasetime = 0
s.acquiretime = 0
s.ticket = 0
//这里是trace相关?
if profile&semaBlockProfile != 0 && blockprofilerate > 0 {
t0 = cputicks()
s.releasetime = -1
}
if profile&semaMutexProfile != 0 && mutexprofilerate > 0 {
if t0 == 0 {
t0 = cputicks()
}
s.acquiretime = t0
}
for {
//调用lock锁定root,这里的锁定是m级别的,其实现与`sync.Mutex`的区别在于这里的lock会使得M休眠
lockWithRank(&root.lock, lockRankRoot)
//添加root的等待者数量
//为后面快速判断是否有waiter准备,nwait==0说明不用唤醒g
atomic.Xadd(&root.nwait, 1)
//再次判断信号量存量
//这里的操作有点类似双重校验锁的思想
if cansemacquire(addr) {
//获取成功,减少等待者数量,释放锁,返回
atomic.Xadd(&root.nwait, -1)
unlock(&root.lock)
break
}
//将当前的g的信息放入到Treap节点对应的队列中
//lifo决定是放入队头还是队尾
root.queue(addr, s, lifo)
//调用gopark休眠当前g
//&root.lock是为了在g与p在解除绑定关系之后调用unlock()方法解锁
goparkunlock(&root.lock, waitReasonSemacquire, traceEvGoBlockSync, 4+skipframes)
//到这一步是唤醒状态
//s.ticket!=0,证明在饥饿模式下已经获取了信号量,不用再尝试获取信号量
//非饥饿模式下需要再次调用cansemacquire尝试获取信号量,若获取失败则继续循环
if s.ticket != 0 || cansemacquire(addr) {
break
}
}
if s.releasetime > 0 {
blockevent(s.releasetime-t0, 3+skipframes)
}
//将sudog放入资源池,重复利用
releaseSudog(s)
}
这里可以看到逻辑比较简单:
- 首先
easy case,尝试简单的通过cas获取信号量,如果获取成功,则直接返回。 -
接下来便是通过
easy case失败,则先初始化属性,调用acquireSudog()方法获取缓存的sudog结构体,这里属性初始化放在加锁之前,能少减少持有锁的时间,提高性能。 -
然后开始准备加锁准备休眠,在休眠之前会再次尝试获取信号量,避免
easy case和加锁过程中信号量发生变化而未检测出来。 -
再然后如果加锁后信号量依然获取失败,则调用
root.queue(addr, s, lifo)尝试找到addr的节点,并进行入队。 -
入队完毕之后准备休眠,等待唤醒
这里不是直接调用
gopark()方法而是调用了goparkunlock(),这个方法相比gopark()多一步在解除g与p的绑定关系之后,调用unlock()方法解锁,为什么不能直接先调用unlock()再调用gopark()呢?仔细思考可以想出来,如果调用
unlock()之后,其他g成功获取锁,同时调用此goready()将g唤醒,此时会出现同一个g绑定在两个p上的错误场景。因此必须在解绑之后再释放锁。 - 唤醒之后判断是否是饥饿模式唤醒,如果是,则表示成功获取信号量,直接退出循环。
-
否则调用
cansemacquire()再次尝试获取信号量,如果获取失败,则继续休眠。 -
最后释放
sudog,将其放入缓存池中。
这里简单分析下sudog的两级缓存。
func acquireSudog() *sudog {
//调用acquirem 避免gc循环死锁,具体原因可以查看源码注释
mp := acquirem()
//获取与m绑定的p
pp := mp.p.ptr()
//如果p中的sudog缓存数量为0
if len(pp.sudogcache) == 0 {
//加锁,这里锁定的对象是一个全局变量
lock(&sched.sudoglock)
//从全局缓存中获取最多容量的一半的结构体到p缓存中
for len(pp.sudogcache) < cap(pp.sudogcache)/2 && sched.sudogcache != nil {
s := sched.sudogcache
sched.sudogcache = s.next
s.next = nil
pp.sudogcache = append(pp.sudogcache, s)
}
//释放锁
unlock(&sched.sudoglock)
//如果本地缓存数量依然是0
if len(pp.sudogcache) == 0 {
//调用new 生成一个新的sudog
pp.sudogcache = append(pp.sudogcache, new(sudog))
}
}
//将获取的sudog出队
n := len(pp.sudogcache)
s := pp.sudogcache[n-1]
pp.sudogcache[n-1] = nil
pp.sudogcache = pp.sudogcache[:n-1]
if s.elem != nil {
throw("acquireSudog: found s.elem != nil in cache")
}
//释放占用标记
releasem(mp)
return s
}
可以看到这里的两级缓存一级来源于全局的sched,这是一个全局变量,用于保存一些全局属性以及调度相关的状态,访问一级缓存需要加锁,因此性能较低,每次需要批量获取。
二级缓存则是p私有的,因此访问二级缓存不需要加锁。通过一级缓存加二级缓存,能更好的利用缓存,避免重复创建对象。
semrelease
接下来看信号量的释放,明白了信号量的获取,应该可以想到释放锁一般就是以下步骤:
cas增加信号量- 查看收否有等待的
g - 如果有,则唤醒
func semrelease1(addr *uint32, handoff bool, skipframes int) {
//获取addr对应semaTable的跟节点
root := semroot(addr)
//信号量加一
atomic.Xadd(addr, 1)
//注意执行到这里+1之后,可能会有其他g刚好执行semacquire1()通过fast path获取到信号量
//因此后面需要再次判断cansemacquire
//如果nwait等于0,则不用唤醒
if atomic.Load(&root.nwait) == 0 {
return
}
//锁定
lockWithRank(&root.lock, lockRankRoot)
//再次判断等待者数量,防止在等待锁定的时候waiter数量归0
if atomic.Load(&root.nwait) == 0 {
unlock(&root.lock)
return
}
//获取addr对应的节点
s, t0 := root.dequeue(addr)
//获取成功waiter数量减一,准备唤醒waiter
if s != nil {
atomic.Xadd(&root.nwait, -1)
}
//这里先解锁,因为yield操作比较慢
unlock(&root.lock)
if s != nil { // May be slow or even yield, so unlock first
acquiretime := s.acquiretime
if acquiretime != 0 {
mutexevent(t0-acquiretime, 3+skipframes)
}
//在dequeue的时候会将ticket归0
//这里再次检查避免影响后面的if s.ticket==1的判断
if s.ticket != 0 {
throw("corrupted semaphore ticket")
}
//如果是饥饿模式,那么再次尝试获取信号量
if handoff && cansemacquire(addr) {
//获取成功,通过ticket做标记
s.ticket = 1
}
//将g与p绑定。同时这里的g被设置为对应p的runnext,作为当前P的下一个调度对象
readyWithTime(s, 5+skipframes)
if s.ticket == 1 && getg().m.locks == 0 {
// 为饥饿模式的g加快调用速度
// 前面readyWithTime()将需要唤醒的g设置到当前p的runnetx节点下面
// goyield()会将当前g从p解绑,并存放在p本地队列中,这样调用goyield()之后,p会立即调度需要唤醒的g
goyield()
}
}
}
小结
从semacquire逻辑来看,其实sema就是一个计数器,根据计数器的值从而休眠或唤醒g。当然对于sema我们不会直接在代码中直接使用,而是将其进一步封装成不同的对象,例如sync.WaitGroup sync.Mutex 等。不同组件的计数值不一样,例如对应sync.Mutex来说,其信号量只能为0或1。从sema在golang中的位置来说,其作用可以和Java的AQS进行类比。