继续看m,在golang中没有对m的状态的枚举,但是我们依然可以根据其代码运行过程,将其分为以下几种状态:
这里我们模仿之前
G和P的状态枚举,列举出M的状态枚举
- 新建状态(
_Mnew):此时m完成OS Thread创建,完成g0的初始化,等待绑定p然后执行schedule() - 调度状态(
_Msched):此时m成功绑定p,并开始执行schedule()方法查找可执行的g - 运行状态(
_Mrunning): 此时m通过findrunnable()成功获取g,并通过切换栈指针开始运行g的指令。 - 自旋状态(
_Mspinning):此时m数量比较多,g数量比较少,因此存在少部分m虽然绑定了p,但是没有g让其运行,此时m会按照:检查定时任务->查找本地队列->查找全局队列->查找netpoller->查找其他的p的顺序依次查找是否存在可运行的g,如果依然未成功查找到可运行的g,则m会解绑p并进入休眠状态。 -
系统调用状态(
_Msyscall): 当g需要进行系统调用时,此时m会先与p解绑,然后执行系统调用,当系统调用返回时,如果之前的p已经被其他m绑定,则m进入休眠状态,否则m继续绑定之前的p运行。 - 休眠状态
(_Mpark): 当m被创建,但是无法获取到空闲p时,m会进入休眠状态,然后等待再次唤醒继续执行。
startm()
一般来说,只要存在g从其他状态转换为_Grunnable状态时,都会调用startm()函数尝试唤醒或新建一个m来执行调度任务。
//runtime#proc.go
func startm(_p_ *p, spinning bool) {
mp := acquirem()
lock(&sched.lock)
if _p_ == nil {
//尝试获取空闲的p
_p_ = pidleget()
//如果没有空闲的p,则直接返回
if _p_ == nil {
unlock(&sched.lock)
//恢复nmspinning的数量,如果spining为true,则说明在调用startm之前已经增加了spinning的数量
if spinning {
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("startm: negative nmspinning")
}
}
releasem(mp)
return
}
}
//获取休眠的m。如果获取失败,则调用newm()创建一个新的m
nmp := mget()
if nmp == nil {
id := mReserveID()
unlock(&sched.lock)
var fn func()
if spinning {
// The caller incremented nmspinning, so set m.spinning in the new M.
fn = mspinning
}
//创建一个新的m
newm(fn, _p_, id)
// Ownership transfer of _p_ committed by start in newm.
// Preemption is now safe.
releasem(mp)
return
}
//获取休眠的m成功,则设置nextp属性,唤醒m
//m被唤醒后会首先通过nextp属性绑定p
unlock(&sched.lock)
if nmp.spinning {
throw("startm: m is spinning")
}
if nmp.nextp != 0 {
throw("startm: m has p")
}
if spinning && !runqempty(_p_) {
throw("startm: p has runnable gs")
}
//设置属性
nmp.spinning = spinning
nmp.nextp.set(_p_)
//唤醒m
notewakeup(&nmp.park)
releasem(mp)
}
从上面的代码可以看出,对于startm():
- 首先,尝试获取空闲的
p,由于m必须先绑定p才能运行,因此p的数量决定了能同时处于运行状态的m的数量 - 如果成功获取
p,则先尝试唤醒处于休眠状态的m - 如果获取成功,则设置相关属性,然后唤醒
m - 否则,调用
newm(),初始化g0、mcache等信息,绑定p,然后运行schedule()
startm()主要是创建新的m,使其进入调度状态。
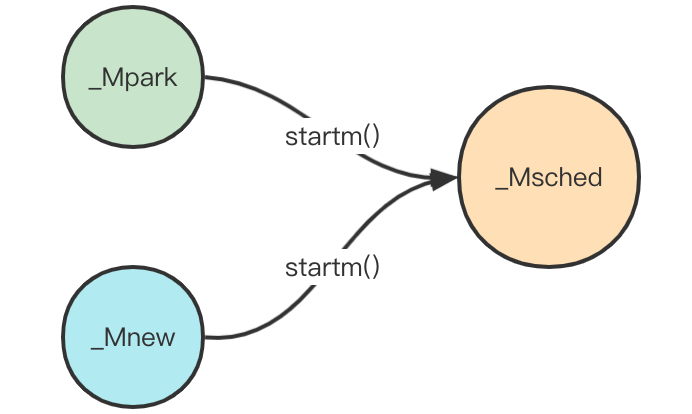
schedule()
接下来继续看schedule():
schedule()是GMP模型中核心中的核心,其包含了GMP相互配合的主要内容。
在分析schedule()方法之前,首先需要说明一下处于spinning状态的m:
golang为了使得新创建的g能够快速被调度,在m查找完:
- 本地运行队列
- 全局运行队列
netpoll
之后,如果依然没有成功获取到g,则部分m会进入spinning状态,对于spinning状态的m,一定是先发现本地队列没有任务才会转变为spinning状态,当成功切换为spinning状态时,其会再次检查:
- 其他
p的运行队列 GC任务队列- 定时任务队列
如果依然没有找到,处于spinning状态的m才会休眠。
每当有g进入_Grunnable状态前,都会先检查是否存在spinning状态的m,如果存在,则不用再唤醒或创建新的m,因为此时新的g一定会被处于spinning状态的m捕获并执行。同时,每当m在成功获取g并开始执行之前,都会先检查当前是否存在处于spinning状态的m的数量是否小于1,如果小于1,则会在执行任务之前先创建一个处于spinning状态的m,以保证g能够被及时调度。
func schedule() {
_g_ := getg()
//检查m是否被锁定
if _g_.m.locks != 0 {
throw("schedule: holding locks")
}
if _g_.m.lockedg != 0 {
stoplockedm()
execute(_g_.m.lockedg.ptr(), false) // Never returns.
}
if _g_.m.incgo {
throw("schedule: in cgo")
}
top:
pp := _g_.m.p.ptr()
pp.preempt = false
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
if pp.runSafePointFn != 0 {
runSafePointFn()
}
//检查m的状态,一般来说如果p存在待执行的g,那么m不应该处于spining状态
if _g_.m.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) {
throw("schedule: spinning with local work")
}
//检查是否存在需要执行的timer
checkTimers(pp, 0)
var gp *g
var inheritTime bool
// Normal goroutines will check for need to wakeP in ready,
// but GCworkers and tracereaders will not, so the check must
// be done here instead.
tryWakeP := false
if trace.enabled || trace.shutdown {
gp = traceReader()
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
traceGoUnpark(gp, 0)
tryWakeP = true
}
}
if gp == nil && gcBlackenEnabled != 0 {
gp = gcController.findRunnableGCWorker(_g_.m.p.ptr())
if gp != nil {
tryWakeP = true
}
}
if gp == nil {
//每调度61次就从全局运行队列中获取一次任务,防止全局队列中的g饥饿
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
//尝试从本地队列中获取g
gp, inheritTime = runqget(_g_.m.p.ptr())
}
if gp == nil {
//如果前面都没有成功获取到g,则调用findrunable查找可运行的g
//findrunnable返回一定是找到了可执行的g,否则就阻塞
gp, inheritTime = findrunnable()
}
//成功获取g
//如果此时m属于spinning状态,由于此时m成功获取任务,也就不属于spinning状态的m
//因此需要检查剩余spinning状态的m的数量,如果小于1则创建获唤醒新的m
if _g_.m.spinning {
resetspinning()
}
if sched.disable.user && !schedEnabled(gp) {
// Scheduling of this goroutine is disabled. Put it on
// the list of pending runnable goroutines for when we
// re-enable user scheduling and look again.
lock(&sched.lock)
if schedEnabled(gp) {
// Something re-enabled scheduling while we
// were acquiring the lock.
unlock(&sched.lock)
} else {
sched.disable.runnable.pushBack(gp)
sched.disable.n++
unlock(&sched.lock)
goto top
}
}
// GC相关
if tryWakeP {
wakep()
}
//如果发现获取的g已经绑定到了对应的m上,则此m会将绑定的p让给被绑定m
//使得g所绑定的m被唤醒并执行
if gp.lockedm != 0 {
startlockedm(gp)
goto top
}
//执行g
execute(gp, inheritTime)
}
在前面g的状态分析中,我们知道schedule()实际上是一个schedule()->execute()->gogo()->schedule()的循环,因此schedule()函数的主要作用其实便是:
- 检查定时器
- 检查是否需要执行全局队列中的任务,每执行61次调度就会从全局队列中偷取一半的任务到本地队列中。
- 通过
findrunable()阻塞直到成功获取g - 检查
gc - 检查
g是否绑定了m - 执行
g
到这里可以看到,总体便是尝试获取g,然后执行。这里面包含一个关键函数:findrunnable(),我们先补充状态图,然后再分析关键函数findrunnable():
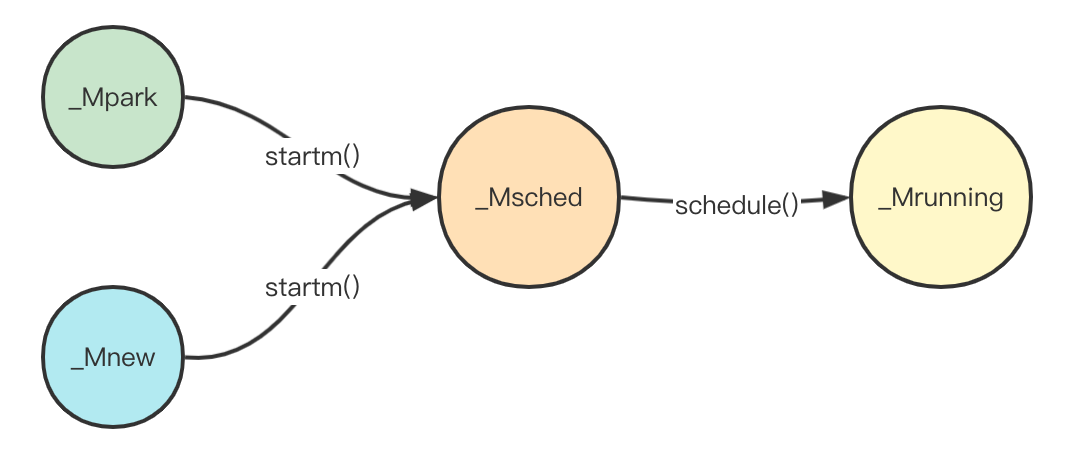
findrunnable()
findrunnable()其实也是一个循环,他会一直循环到成功获取到g,否则会调用stopm()休眠m.
func findrunnable() (gp *g, inheritTime bool) {
_g_ := getg()
top:
_p_ := _g_.m.p.ptr()
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
if _p_.runSafePointFn != 0 {
runSafePointFn()
}
//检查定时任务
now, pollUntil, _ := checkTimers(_p_, 0)
if fingwait && fingwake {
if gp := wakefing(); gp != nil {
ready(gp, 0, true)
}
}
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
//检查本地运行队列是否存在任务
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
//检查全局队列是否存在任务
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
//检查netpoll是否存在待执行的fd
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
//如果上面的任务中,都没有成功获取到待运行的g,则部分m会进入spinnning状态
//为了在并行度不高的情况下不过分浪费CPU, spinning状态的m的数量需要少于idle p的数量的一半。
procs := uint32(gomaxprocs)
if _g_.m.spinning || 2*atomic.Load(&sched.nmspinning) < procs-atomic.Load(&sched.npidle) {
if !_g_.m.spinning {
//切换到spinning状态
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
//从其他p窃取任务,如果存在p需要窃取,则会直接窃取一半到当前p
gp, inheritTime, tnow, w, newWork := stealWork(now)
now = tnow
//如果窃取成功,则返回
if gp != nil {
return gp, inheritTime
}
//如果未窃取成功,但是在窃取过程中运行过定时任务,则可能又有新的任务加入
//此时重新开始循环
if newWork {
// There may be new timer or GC work; restart to
// discover.
goto top
}
if w != 0 && (pollUntil == 0 || w < pollUntil) {
// Earlier timer to wait for.
pollUntil = w
}
}
//实在无法获取到任务,先检查GC
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(_p_) {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
_p_.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
// wasm only:
gp, otherReady := beforeIdle(now, pollUntil)
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
if otherReady {
goto top
}
// 准备释放p然后休眠
allpSnapshot := allp
// Also snapshot masks. Value changes are OK, but we can't allow
// len to change out from under us.
idlepMaskSnapshot := idlepMask
timerpMaskSnapshot := timerpMask
// return P and block
lock(&sched.lock)
if sched.gcwaiting != 0 || _p_.runSafePointFn != 0 {
unlock(&sched.lock)
goto top
}
//再次检查全局运行队列
if sched.runqsize != 0 {
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
return gp, false
}
//释放p
if releasep() != _p_ {
throw("findrunnable: wrong p")
}
//将p放入idlep队列
pidleput(_p_)
unlock(&sched.lock)
wasSpinning := _g_.m.spinning
//如果当前m是spinning状态
if _g_.m.spinning {
//恢复状态值
_g_.m.spinning = false
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("findrunnable: negative nmspinning")
}
//注意下面的操作是在已经减少了spinning状态的m的数量的情况下操作
//主要是为了保证只要在检查nmspinning>0时,提交的任务一定会被执行
//再次遍历所有的p查看p本地队列是否有任务
_p_ = checkRunqsNoP(allpSnapshot, idlepMaskSnapshot)
if _p_ != nil {
acquirep(_p_)
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
goto top
}
//再次检查是否有GC任务需要执行
_p_, gp = checkIdleGCNoP()
if _p_ != nil {
acquirep(_p_)
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
// Run the idle worker.
_p_.gcMarkWorkerMode = gcMarkWorkerIdleMode
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
//再次检查定时任务
pollUntil = checkTimersNoP(allpSnapshot, timerpMaskSnapshot, pollUntil)
}
// 检查netpoll
if netpollinited() && (atomic.Load(&netpollWaiters) > 0 || pollUntil != 0) && atomic.Xchg64(&sched.lastpoll, 0) != 0 {
atomic.Store64(&sched.pollUntil, uint64(pollUntil))
if _g_.m.p != 0 {
throw("findrunnable: netpoll with p")
}
if _g_.m.spinning {
throw("findrunnable: netpoll with spinning")
}
delay := int64(-1)
if pollUntil != 0 {
if now == 0 {
now = nanotime()
}
delay = pollUntil - now
if delay < 0 {
delay = 0
}
}
if faketime != 0 {
// When using fake time, just poll.
delay = 0
}
list := netpoll(delay) // block until new work is available
atomic.Store64(&sched.pollUntil, 0)
atomic.Store64(&sched.lastpoll, uint64(nanotime()))
if faketime != 0 && list.empty() {
//发现没有网络任务,则休眠m,直到被唤醒
//被唤醒后又会进入top从新开始遍历
stopm()
goto top
}
lock(&sched.lock)
//因为在上面已经释放了P,所以这里需要重新获取p执行任务
_p_ = pidleget()
unlock(&sched.lock)
if _p_ == nil {
injectglist(&list)
} else {
acquirep(_p_)
if !list.empty() {
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
goto top
}
} else if pollUntil != 0 && netpollinited() {
pollerPollUntil := int64(atomic.Load64(&sched.pollUntil))
if pollerPollUntil == 0 || pollerPollUntil > pollUntil {
netpollBreak()
}
}
//没有网络任务,则直接休眠直到被唤醒
//被唤醒后又会进入top从新开始遍历
stopm()
goto top
}
代码比较长,但是其实总结起来就是:
- 首先,尝试从各个可能存储任务的地方获取任务,包括定时任务、本地队列、全局队列、
netpoll等。 - 如果实在无法获取任务,则挑选一部分
m进入spinning状态,对于spinning状态的m,可以在有新的g创建时快捷检测是否有处于spinning状态的m,如果有,则不用再重新唤醒m,因为处于spinning状态的m一定能成功获取到g并执行。 - 同时,
spinning状态的m还会尝试去窃取其他p的本地队列,查看是否有可执行的p,如果有则偷取一半到本地队列中。 - 如果实在无法获取到
g,则释放p,恢复spinning状态,最后再依次检查一遍:所有p的本地队列、GC任务、定时任务 - 如果还是没有任务,则调用
stopm休眠,等待被唤醒 - 唤醒后再次进入
top重新循环。
这里,可以根据findrunnable()继续补充m的状态图:
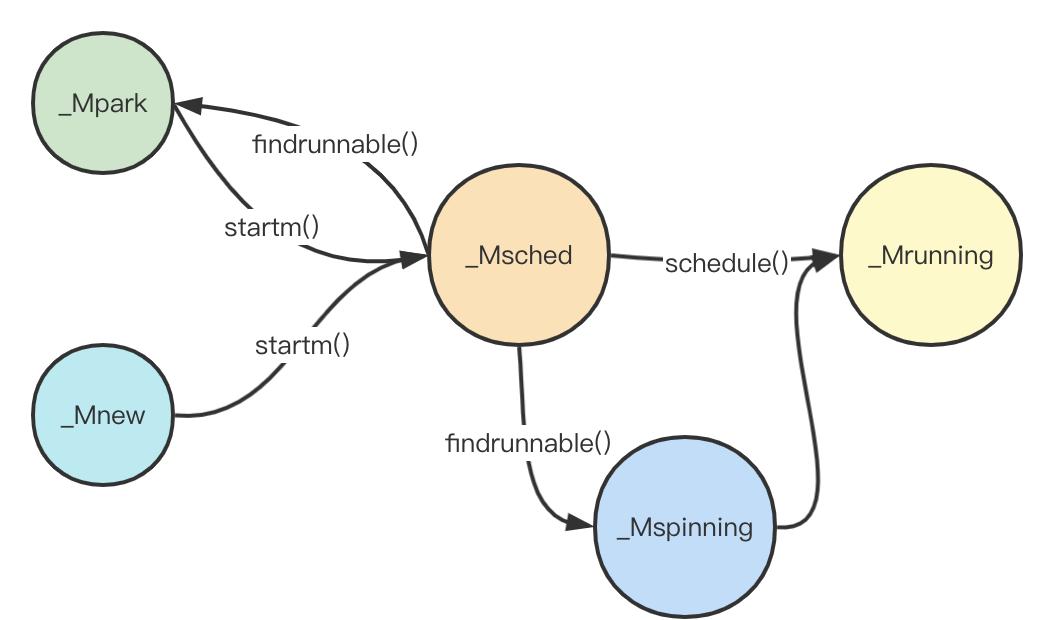
syscall
对于m来说,最后一个状态便是syscall。
其实syscall状态没有什么好说的,但是这是唯一一个m不需要绑定p也能继续运行的状态。
对于所有syscall函数,golang最后都会调用到下面的方法:
func syscall_syscall(fn, a1, a2, a3 uintptr) (r1, r2, err uintptr) {
//进入syscall状态
entersyscall()
//执行syscall
libcCall(unsafe.Pointer(abi.FuncPCABI0(syscall)), unsafe.Pointer(&fn))
//syacall执行完毕
exitsyscall()
return
}
这里面具体的代码已经在p状态流转中分析完毕,因此不再详细描述,我们简单过一下流程:
- 首先,在执行系统调用之前,
m会将p解绑,p进入_Psyscall状态 - 然后,
m开始执行系统调用代码,一般系统调用会进入内核态并阻塞 - 当
m系统调用执行完毕之后,会调用exitsyscall()函数尝试重新绑定p继续运行 - 如果
p绑定失败,则m会将当前的g放入全局队列中,然后休眠。
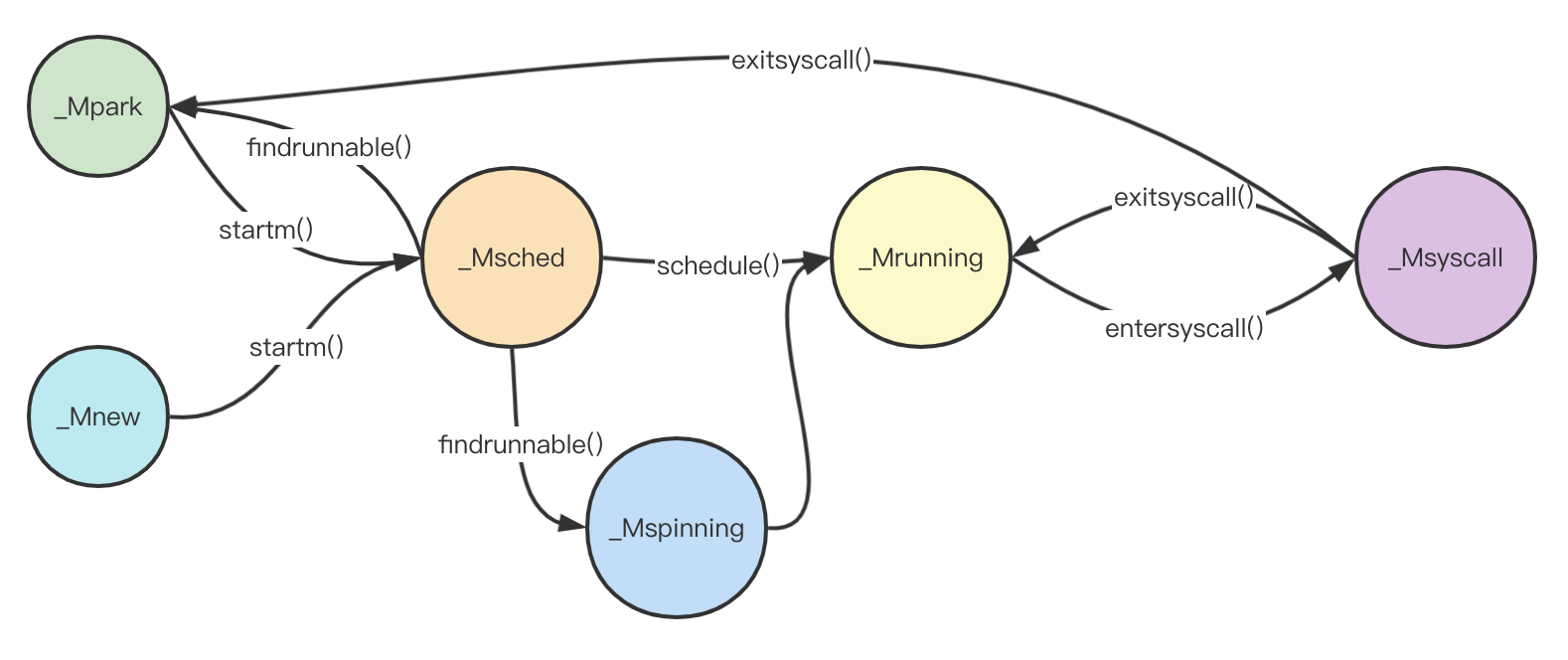
自此,m的状态图补充完毕。虽然m的状态图比较多,但其实总体来说m就两种状态,运行和阻塞。
上面的状态图只是根据m具体运行的代码细分出来的状态,在golang源码中并没有枚举。
总体来说,m主要的任务便是查找可运行的g,然后执行,如果实在查找不到,则进入阻塞状态等待被唤醒。