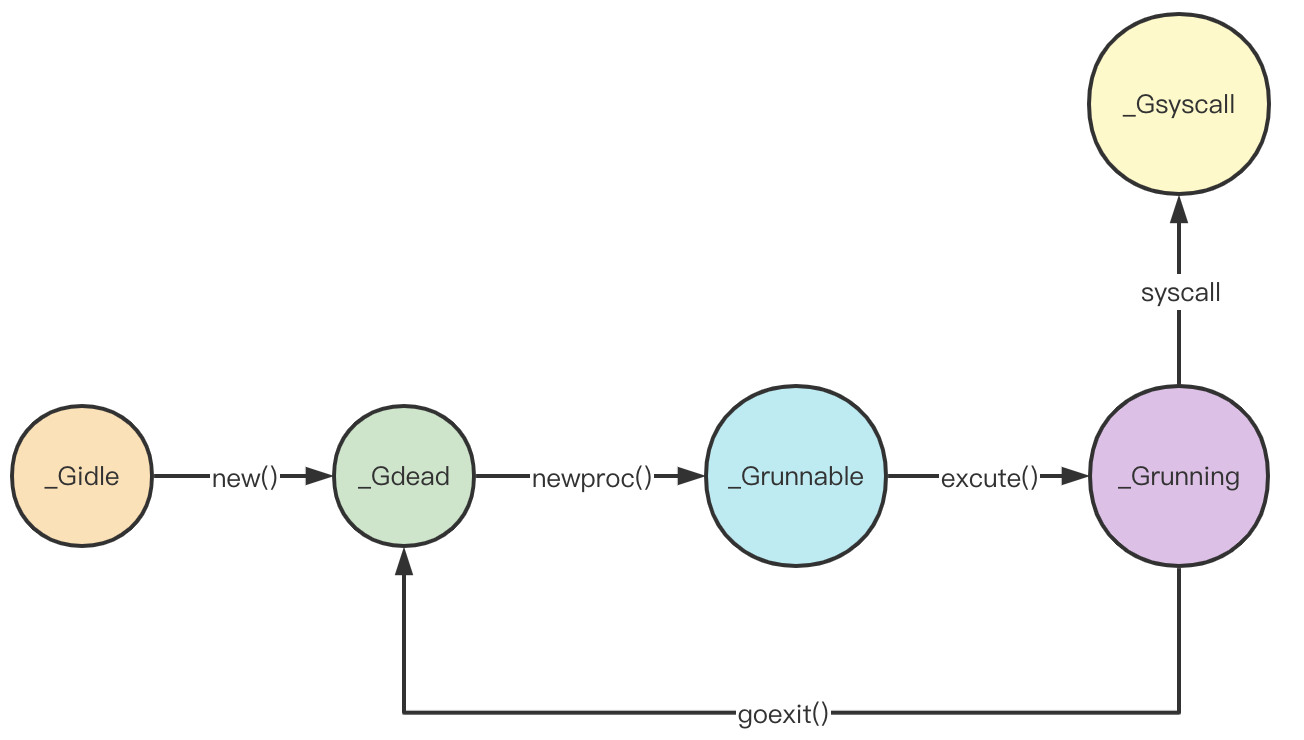
在上一章内容中,我们了解的G的生命周期,接下来我们继续第一章中简版GMP模型中留下的问题;
G的中断
当我们执行系统调用时,如果不进行特殊处理,则会阻塞M,进而使得整个系统被拖慢,在golang中,通过系统调用源码可以找到,所有的系统调用最终都是通过syscall()实现:
// Implemented in the runtime package (runtime/sys_darwin.go)
func syscall(fn, a1, a2, a3 uintptr) (r1, r2 uintptr, err Errno)
这只是函数的声明,从注释中我们可以找到其对应的源码:
//runtime/sys_darwin.go
//go:linkname syscall_syscall syscall.syscall
//go:nosplit
//go:cgo_unsafe_args
func syscall_syscall(fn, a1, a2, a3 uintptr) (r1, r2, err uintptr) {
//系统调用前准备
entersyscall()
//系统调用
libcCall(unsafe.Pointer(abi.FuncPCABI0(syscall)), unsafe.Pointer(&fn))
//系统调用后处理
exitsyscall()
return
}
可以看到在真正系统调用之前和之后,都通过函数进行了相关处理
//runtime.proc.go
func entersyscall() {
//参数1:获取调用者的pc寄存器
//参数2:获取调用者的sp寄存器
//看方法名此方法可重入,也就是可以在系统调用中继续调用系统API
reentersyscall(getcallerpc(), getcallersp())
}
//go:nosplit
func reentersyscall(pc, sp uintptr) {
_g_ := getg()
//禁止抢占
_g_.m.locks++
// Entersyscall must not call any function that might split/grow the stack.
// (See details in comment above.)
// Catch calls that might, by replacing the stack guard with something that
// will trip any stack check and leaving a flag to tell newstack to die.
_g_.stackguard0 = stackPreempt
_g_.throwsplit = true
// Leave SP around for GC and traceback.
//将pc和sp寄存器保存在当前g中
save(pc, sp)
_g_.syscallsp = sp
_g_.syscallpc = pc
//设置g的状态为Gsyscall
casgstatus(_g_, _Grunning, _Gsyscall)
//...
//gc相关
if atomic.Load(&sched.sysmonwait) != 0 {
systemstack(entersyscall_sysmon)
save(pc, sp)
}
if _g_.m.p.ptr().runSafePointFn != 0 {
// runSafePointFn may stack split if run on this stack
systemstack(runSafePointFn)
save(pc, sp)
}
_g_.m.syscalltick = _g_.m.p.ptr().syscalltick
_g_.sysblocktraced = true
pp := _g_.m.p.ptr()
//将p与m解绑
pp.m = 0
//设置oldp字段
_g_.m.oldp.set(pp)
//将m与p解绑
_g_.m.p = 0
//设置p的状态为_Psyscall
atomic.Store(&pp.status, _Psyscall)
if sched.gcwaiting != 0 {
systemstack(entersyscall_gcwait)
save(pc, sp)
}
//解除禁止抢占
_g_.m.locks--
}
从此方法可以看出来,在进行系统调用之前,会先将当前寄存器的信息保存在g中,同时最关键的一步是将此m与p解除绑定,通过此番操作,p进入_Psyscall状态,对与处于_Psyscall状态的p,在调度的时候,会尝试从新绑定一个新的m进而重新进入_Prunning状态。
从这里可以看出来,当一个g执行了阻塞m的系统调用,则与m绑定的p会重新寻找一个空闲m绑定,防止阻塞p中其他待运行的g。
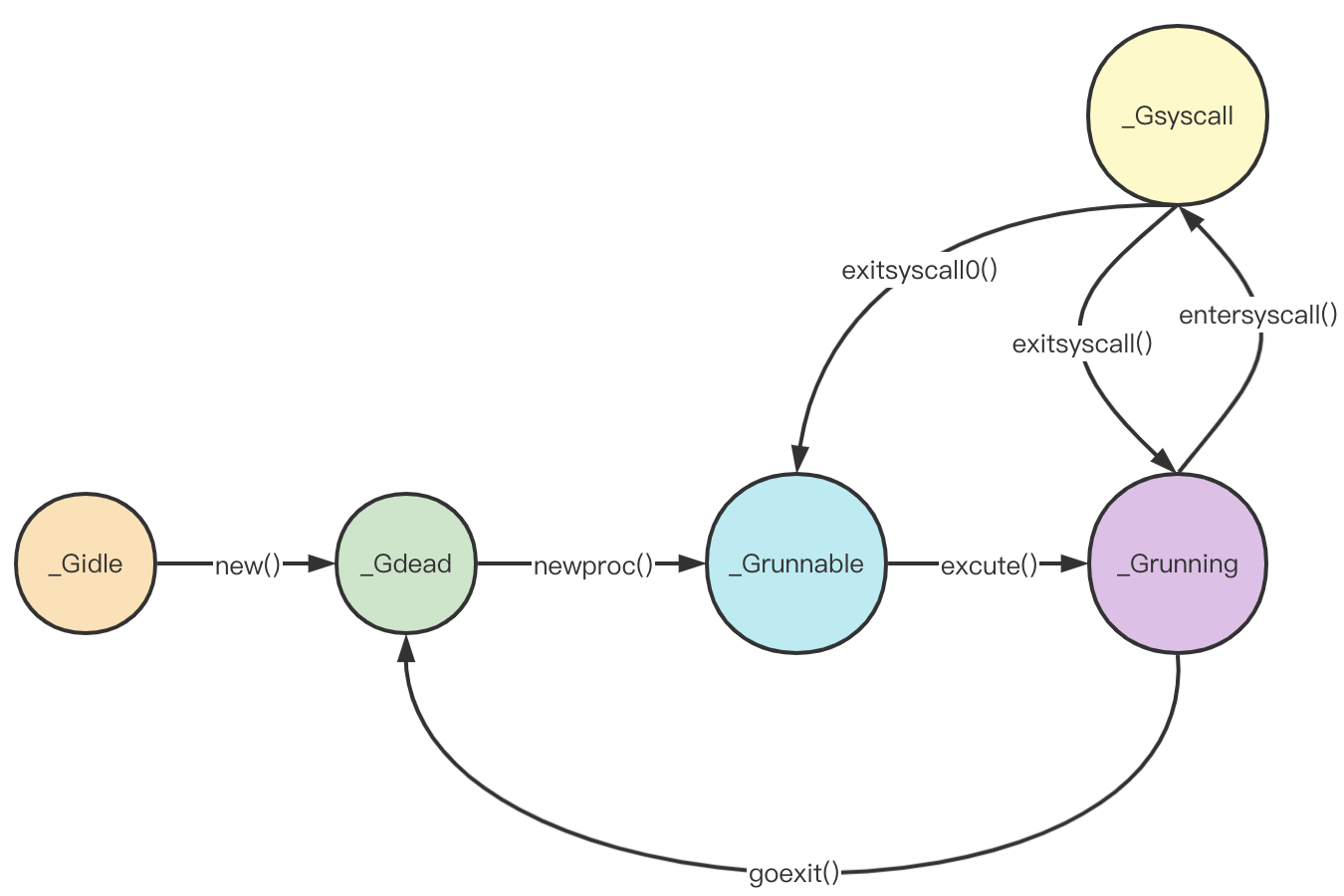
从这里,我们可以继续补充g的状态图:
继续看, 当执行完entersyscall()之后,可以继续syscall,这是真正的系统调用,执行完之后,进入exitsyscall()函数:
func exitsyscall() {
_g_ := getg()
_g_.m.locks++ // see comment in entersyscall
if getcallersp() > _g_.syscallsp {
throw("exitsyscall: syscall frame is no longer valid")
}
_g_.waitsince = 0
oldp := _g_.m.oldp.ptr()
_g_.m.oldp = 0
//尝试快速获取一个p
//首先尝试从之前的oldp获取
//否则查看空闲p列表中是否有空闲的p需要调度
if exitsyscallfast(oldp) {
_g_.m.p.ptr().syscalltick++
//修改g的状态为running
casgstatus(_g_, _Gsyscall, _Grunning)
//恢复系统调用信息
_g_.syscallsp = 0
_g_.m.locks--
//检查抢占信息,恢复栈信息
if _g_.preempt {
// restore the preemption request in case we've cleared it in newstack
_g_.stackguard0 = stackPreempt
} else {
// otherwise restore the real _StackGuard, we've spoiled it in entersyscall/entersyscallblock
_g_.stackguard0 = _g_.stack.lo + _StackGuard
}
_g_.throwsplit = false
if sched.disable.user && !schedEnabled(_g_) {
// Scheduling of this goroutine is disabled.
Gosched()
}
return
}
//如果没有找到空闲的p需要调度
//则将g扔到全局队列,同时让m自旋直到找到p需要调度
_g_.sysexitticks = 0
_g_.m.locks--
mcall(exitsyscall0)
_g_.syscallsp = 0
_g_.m.p.ptr().syscalltick++
_g_.throwsplit = false
}
可以看到,当g所挂载的m 在执行完syscall之后,会执行以下操作:
- 首先,尝试给返回的
m配对一个p:- 首先查看
oldp收否依然没有被其他m绑定,如果没有,则刚好可以继续绑定继续执行剩下的代码。 - 否则,查看是否存在空闲的
p,若有,则与之绑定,然后继续执行剩下的代码。
- 首先查看
- 否则,说明当前没有空闲的
p,则执行exitsyscall0()函数,在exitsyscall0()函数中,主要是再次尝试获取空闲的p,如果依然获取失败,则说明当然已经有足够的m与p绑定,因此当前m需要休眠直到被唤醒 - 在
m休眠之前,会将当前g解除与m的绑定,修改g的状态为_Grunnable并将g扔进全局队列中,让其他正在运行的p来继续调度g。
func exitsyscall0(gp *g) {
//修改g的状态
casgstatus(gp, _Gsyscall, _Grunnable)
//将m与g解绑
dropg()
lock(&sched.lock)
var _p_ *p
//再次尝试获取p
if schedEnabled(gp) {
_p_ = pidleget()
}
var locked bool
//如果依然获取失败
if _p_ == nil {
//将p扔进全局待运行队列
globrunqput(gp)
locked = gp.lockedm != 0
} else if atomic.Load(&sched.sysmonwait) != 0 {
atomic.Store(&sched.sysmonwait, 0)
notewakeup(&sched.sysmonnote)
}
unlock(&sched.lock)
//如果成功获取p,则继续执行调度
if _p_ != nil {
acquirep(_p_)
execute(gp, false) // Never returns.
}
if locked {
stoplockedm()
execute(gp, false) // Never returns.
}
//否则,休眠m直到成功获取p
stopm()
//当stopm()返回的时候,说明此时已经成功获取了p,则继续执行调度
schedule()
}
综上一句话,总结起来便是,当g 需要执行系统调度的时候,m会将当前的p解绑,让其他m绑定p继续执行。等m系统调用完毕之后,m会继续尝试绑定p继续调度,如果当前已经没有空闲的p,则m将g放进全局待运行队列,同时将自己挂起,直到获取到新的p。
到这里,我们可以继续补充g的状态流转图: