GMP中的G是对任务的抽象,其通过g结构体表示,其定义在runtime.runtime2.go中。
G 的创建
当程序中使用go关键字创建一个goroutine时,编译器会将其编译为newproc()函数,用来创建一个新的goroutine。
//runtime#proc.go
//siz 函数参数大小
//fn 需要通过go 执行的func指针
func newproc(siz int32, fn *funcval) {
//参数的起始地址
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
//获取当前运行的g
gp := getg()
//获取调用newproc的函数的pc寄存器
pc := getcallerpc()
//在g0的栈上调用func
systemstack(func() {
//初始化新的g
newg := newproc1(fn, argp, siz, gp, pc)
//获取当前运行的g所绑定的m中所绑定的p
_p_ := getg().m.p.ptr()
//尝试将g放入p的本地队列中
runqput(_p_, newg, true)
if mainStarted {
//尝试唤醒一个p来运行g
wakep()
}
})
}
可以看到总体逻辑为初始化一个新的g,并将其放入创建g的线程对应的p的本地队列中。最后查看是否有自旋的p,如果有则唤醒使其进行调度。
继续看newproc1()
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g {
//获取当前运行的g
_g_ := getg()
//检查fn是否为nil
if fn == nil {
_g_.m.throwing = -1 // do not dump full stacks
throw("go of nil func value")
}
//锁定m,禁止抢占
acquirem() // disable preemption because it can be holding p in a local var
//计算参数大小
siz := narg
//内存对齐
siz = (siz + 7) &^ 7
//如果参数大小比 2K栈减去4字预留大小减去预留的return address还大,则报错
if siz >= _StackMin-4*sys.PtrSize-sys.PtrSize {
throw("newproc: function arguments too large for new goroutine")
}
//获取当前的p
_p_ := _g_.m.p.ptr()
//尝试从当前p中获取缓存的P
newg := gfget(_p_)
//如果没有获取成功,则通过malg创建一个新的g,stack大小为_StackMin (2K)
if newg == nil {
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
if newg.stack.hi == 0 {
throw("newproc1: newg missing stack")
}
if readgstatus(newg) != _Gdead {
throw("newproc1: new g is not Gdead")
}
//计算totalsize
totalSize := 4*sys.PtrSize + uintptr(siz) + sys.MinFrameSize
totalSize += -totalSize & (sys.StackAlign - 1) // align to StackAlign
//函数运行栈的sp寄存器
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
if narg > 0 {
//拷贝参数到栈上
memmove(unsafe.Pointer(spArg), argp, uintptr(narg))
if writeBarrier.needed && !_g_.m.curg.gcscandone {
f := findfunc(fn.fn)
stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps))
if stkmap.nbit > 0 {
// We're in the prologue, so it's always stack map index 0.
bv := stackmapdata(stkmap, 0)
bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata)
}
}
}
//清空sched字段
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
//设置sp寄存器
newg.sched.sp = sp
newg.stktopsp = sp
//设置pc寄存器
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum
//设置g
newg.sched.g = guintptr(unsafe.Pointer(newg))
//调整pc寄存器和sp寄存器
gostartcallfn(&newg.sched, fn)
//设置newproc的pc寄存器地址
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
//设置startpc
newg.startpc = fn.fn
if _g_.m.curg != nil {
newg.labels = _g_.m.curg.labels
}
if isSystemGoroutine(newg, false) {
atomic.Xadd(&sched.ngsys, +1)
}
// Track initial transition?
newg.trackingSeq = uint8(fastrand())
if newg.trackingSeq%gTrackingPeriod == 0 {
newg.tracking = true
}
//修改g当前状态为runable
casgstatus(newg, _Gdead, _Grunnable)
if _p_.goidcache == _p_.goidcacheend {
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
if raceenabled {
newg.racectx = racegostart(callerpc)
}
if trace.enabled {
traceGoCreate(newg, newg.startpc)
}
releasem(_g_.m)
//返回g
return newg
}
newproc1 的主要作用便是新建一个g,从g的初始化流程可以看出来g是如何对一个Task进行抽象的。
- 首先,获取参数大小,这里为什么只需要参数大小,而不需要参数地址,是因为在
newproc的注释中写到:对于newproc栈,参数的是紧邻&fn的地址的,因此通过&fn参数即可推算出参数的地址。 -
然后,计算需要预留的
totalSize,totalSize包含特殊情况需要预留的栈空间+参数大小 -
紧接着,尝试从本地
p获取缓存的g,如果没有缓存的g,则new一个栈大小为2K的g -
接下来计算
sp寄存器的地址。建议回顾一下各个寄存器的作用,sp作为栈指针寄存sp := newg.stack.hi - totalSize此时栈结构如下图所示
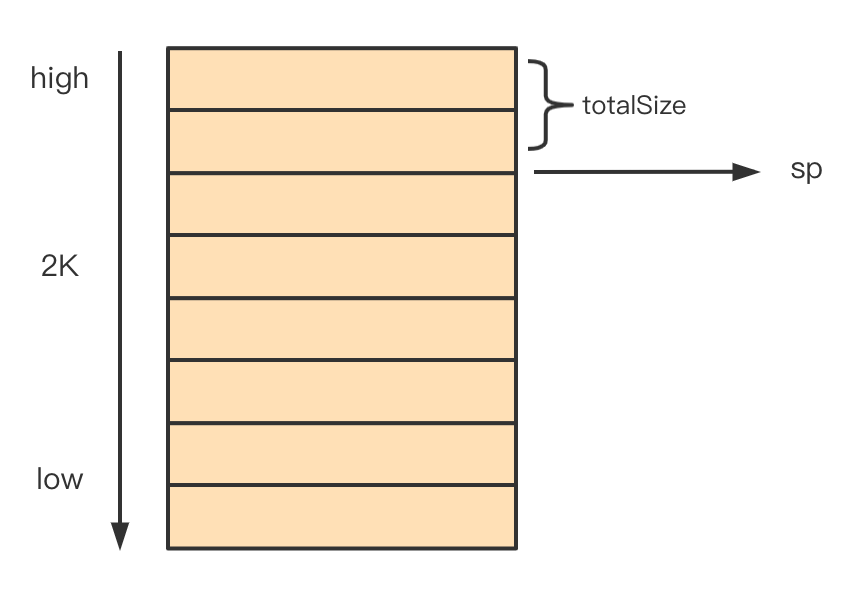
-
memmove(unsafe.Pointer(spArg), argp, uintptr(narg))这一步将
func传入的参数拷贝到栈上,执行这一步之后,g中的stack变成如下图: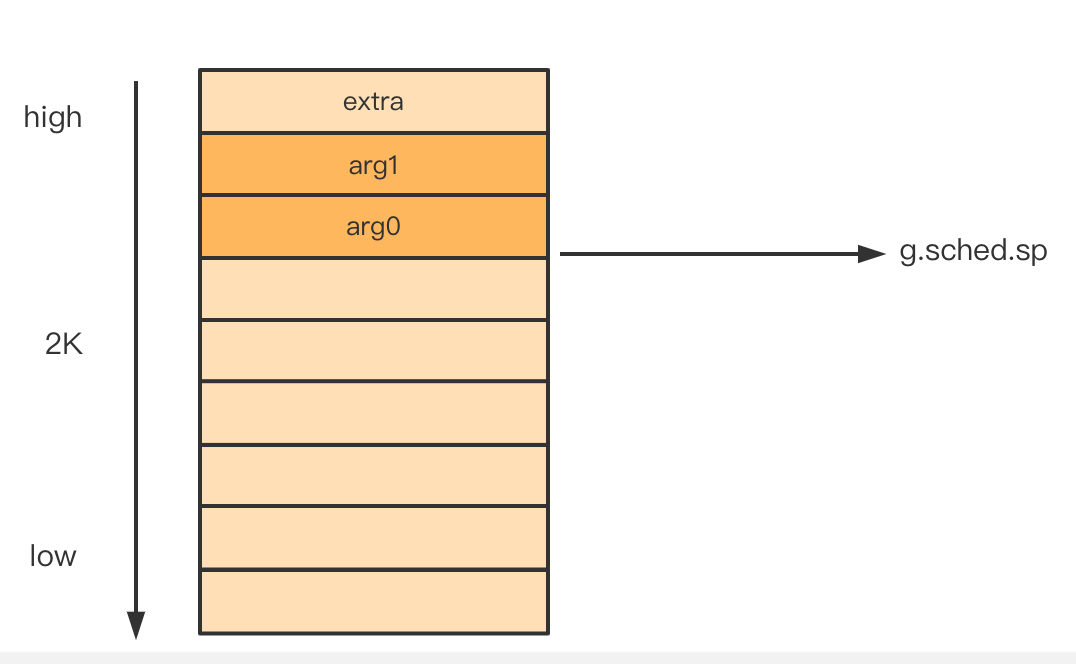
-
接下来,是给
g的sched属性赋值://设置sp寄存器 newg.sched.sp = sp newg.stktopsp = sp //设置pc寄存器 newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum //设置g newg.sched.g = guintptr(unsafe.Pointer(newg)) //调整pc寄存器和sp寄存器 gostartcallfn(&newg.sched, fn) //设置newproc的pc寄存器地址 newg.gopc = callerpc newg.ancestors = saveAncestors(callergp) //设置startpc newg.startpc = fn.fn结合上图,应该都能看懂每一步的操作。唯一比较疑惑的是,为什么
pc寄存器会设置为goexit函数的地址?回顾go寄存器的作用,能够知道pc寄存器是用来指示CPU读取指令地址的寄存器,通过pc寄存器可以实现指令的跳转功能,因此pc寄存器都是指向指令段,那么这里不应该指向&fn么?答案在gostartcallfn(&newg.sched, fn)这一行gostartcall(gobuf, fn, unsafe.Pointer(fv))内部直接调用了gostartcall()函数,因此我们直接看gostartcall()func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) { //获取g.sched.sp sp := buf.sp //sp像下移动一个指针大小 sp -= sys.PtrSize //设置当前sp指向的值为g.sched.pc的值 *(*uintptr)(unsafe.Pointer(sp)) = buf.pc //赋值sp寄存器 buf.sp = sp //修改pc寄存器指向fn buf.pc = uintptr(fn) buf.ctxt = ctxt }这一步首先将
sp寄存器向下移动一个指针大小,然后将其赋值为g.sched.pc的地址,然后再将g.sched.pc的地址修改为fn,为什么要这样设置,回想go 汇编中的函数调用栈,当一个函数通过call指令调用另外一个函数时,会将return address压在栈底,当函数通过ret指令返回时,会通过读取这个return address返回caller。而return address就在sp寄存器指向的位置。通过上面的步骤,此时g中的stack变成了: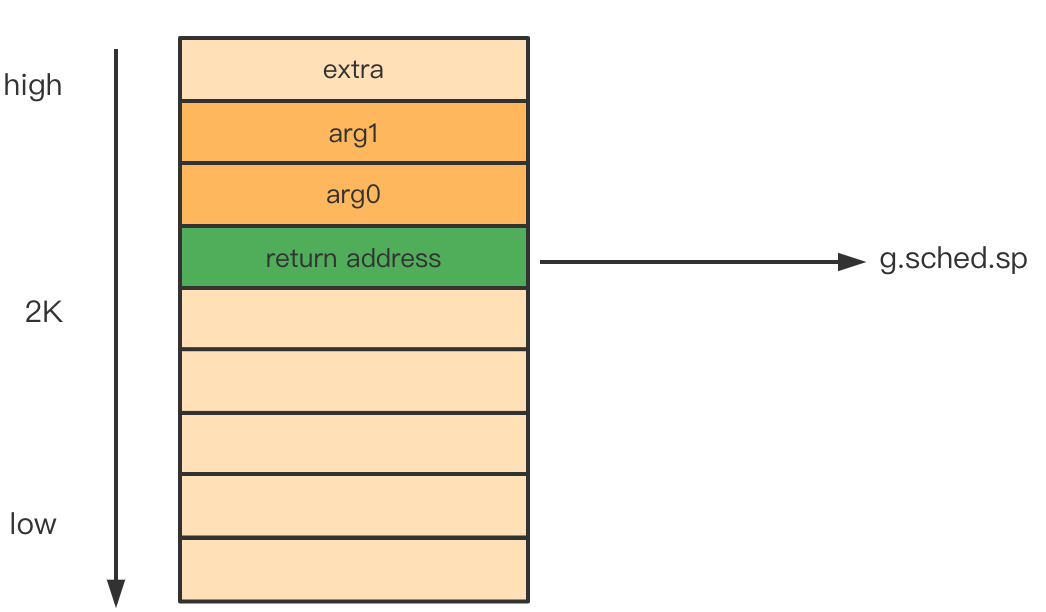
对比真正的函数调用栈:
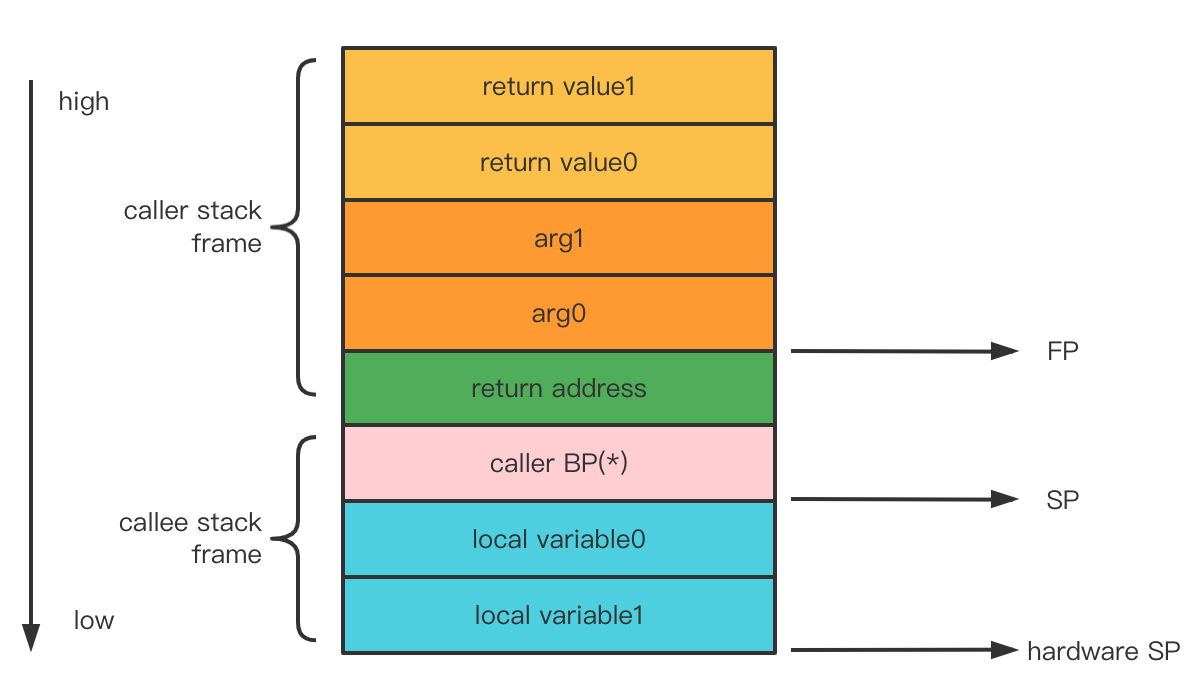
可以发现除了
return value,目前g中的stack已经包含了函数调用栈所需要的其他内容,而go func(){}()并没有返回值,所以这里没有预留返回值的栈空间。这里已经设置了
return address,因此调用func()不能通过call指令,而是需要通过jmp指令再提一个疑问?为什么需要将
return address设置为goexit()函数呢?这和GMP的调度有关,后面再详解。至此,
g创建完毕。剩下便是设置其状态,将其扔进待运行队列,尝试唤醒P开始执行。这里可以根据代码画出一张
G的生命周期图: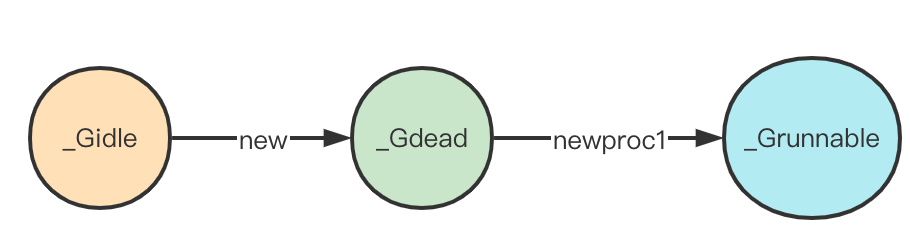
从
G的创建我们可以看出,G其实就是对func的函数调用栈信息的保存,也就是对于g来说,最重要的字段就是sched,其结构体保存了G需要执行的寄存器的所有信息:
type gobuf struct {
//sp 寄存器
sp uintptr
//pc 寄存器
pc uintptr
//所绑定的g
g guintptr
// GC 相关
ctxt unsafe.Pointer
// 保存系统调用的返回值
ret sys.Uintreg
lr uintptr
bp uintptr
}
G 的执行
当g创建完毕之后,会被放在待运行队列中,等待运行,当G成功被M选中之后,G会被载入并执行。
//runtim.proc.go
func schedule(){
//查找可执行的g
...
//查找成功,执行g
execute(gp, inheritTime)
}
execute()函数便是执行g,接着看代码:
func execute(gp *g, inheritTime bool) {
_g_ := getg()
//设置当前m正在运行的g为gp
_g_.m.curg = gp
//设置当前g所绑定的m
gp.m = _g_.m
//将g的状态由_Grunable切换为_Grunning
casgstatus(gp, _Grunnable, _Grunning)
//初始化调度相关信息
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
//...
//调用gogo执行g
gogo(&gp.sched)
}
可以看到execute()也只是修改了g相关的一些状态,继续看gogo,可以看到想要执行g,仅仅需要g的sched字段即可, 由于g.sched保存的是寄存器相关的信息,因此想要真正的执行g,只能通过汇编实现,因此gogo()对应的源码也是汇编:
//runtime.asm_amd64.s
TEXT runtime·gogo(SB), NOSPLIT, 0-8
//设置参数buf到BX寄存器
MOVQ buf+0(FP), BX // gobuf
//获取buf.g 到DX寄存器
MOVQ gobuf_g(BX), DX
//测试g是否为nil
MOVQ 0(DX), CX // make sure g != nil
JMP gogo<>(SB)
TEXT gogo<>(SB), NOSPLIT,0
//获取tls[0]的指针,将其保存在CX寄存器
get_tls(CX)
//将buf.g保存在tls[0]中,使得程序可以通过get_tls()获取当前正在执行的`g`
MOVQ DX, g(CX)
MOVQ DX, R14 // set the g register
//设置sp寄存器
MOVQ gobuf_sp(BX), SP
//设置返回值
MOVQ gobuf_ret(BX), AX
MOVQ gobuf_ctxt(BX), DX
//设置bp寄存器
MOVQ gobuf_bp(BX), BP
//因为已经载入到CPU中,因此这里可以清空sched的属性值,对GC更友好
MOVQ 0, gobuf_sp(BX) MOVQ0, gobuf_ret(BX)
MOVQ 0, gobuf_ctxt(BX)
MOVQ0, gobuf_bp(BX)
//获取pc寄存器的值
MOVQ gobuf_pc(BX), BX
//跳转到pc寄存器指向的指令地址
JMP BX
可以看到gogo()通过读取sched字段的各个属性,进而设置寄存器的值,最后通过JMP即可跳转到对应的func进行执行。这里为什么使用的是JMP指令而不是Call,在前文已有解释,其主要原因是return address已经提前设置,所以这里并不需要再将return address压栈。
到这里,我们可以继续完善g的状态图:

G 的终止
前面说过,在新建g是,将函数goexit()的地址设置为了return address,也就是func在执行完毕之后,会执行goexit(),这里我们简单看下goexit()
//runtime.proc.go
func goexit1() {
if raceenabled {
racegoend()
}
if trace.enabled {
traceGoEnd()
}
//通过g0调用goexit0
mcall(goexit0)
}
//runtime.proc.go
func goexit0(gp *g) {
//获取当前运行的g
_g_ := getg()
//修改gp运行状态
casgstatus(gp, _Grunning, _Gdead)
if isSystemGoroutine(gp, false) {
atomic.Xadd(&sched.ngsys, -1)
}
//清空g的属性,方便复用
gp.m = nil
locked := gp.lockedm != 0
gp.lockedm = 0
_g_.m.lockedg = 0
gp.preemptStop = false
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = 0
gp.param = nil
gp.labels = nil
gp.timer = nil
//..
//将g从p的队列中删除
dropg()
//..
if _g_.m.lockedInt != 0 {
print("invalid m->lockedInt = ", _g_.m.lockedInt, "\n")
throw("internal lockOSThread error")
}
//将g放回p的缓存队列,等待复用
gfput(_g_.m.p.ptr(), gp)
if locked {
if GOOS != "plan9" { // See golang.org/issue/22227.
gogo(&_g_.m.g0.sched)
} else {
// Clear lockedExt on plan9 since we may end up re-using
// this thread.
_g_.m.lockedExt = 0
}
}
//继续调度下一个g,且不会返回
schedule()
}
从goexit0()源码可以明白为什么需要插入goexit()函数了,因为goexit()函数主要负责清理和回收执行完毕的g,当清理完毕后,又会继续调度下一个g。
到这里,g的生命周期便形成了一个闭环:
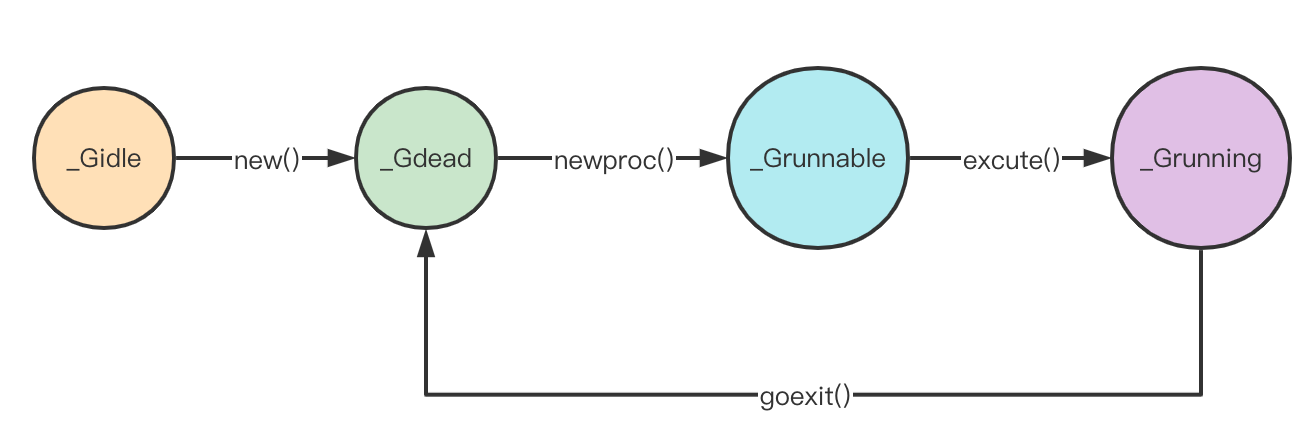
从整个的g创建->待执行->执行->清理的过程中,可以看出来,g实际上就是一个待执行的Task,这和我们第一章创建的简版的GMP的概率相符合。