Go Goroutine
在刚接触Go的时候,了解到Go特色之一便是协程,Go通过在用户态管理程序中所有的协程,使得其在Web方面能够轻松支撑起百万连接。这里简单梳理下协程与线程的区别以及Go如何解决协程中的问题。
为什么要有协程?
在早期的Windows 3.x,多进程直接之间都是协作式任务。每个任务的执行都需要等到上一个任务主动让出CPU才有机会开始执行。这样实现的方式的缺点就很明显,如果某个进程不守规矩,直接while(true)循环,那么会导致整个系统都陷入瘫痪。
于是从Windows 95开始,进程的调度修改为抢夺式调度:也就是每个进程都只能占用固定时间的CPU,时间片到期后CPU会强制进程休眠。通过时间片的分配,能够真正的保证一个进程的执行不会影响到其他进程。
随着计算机的发展以及多核CPU的普及,单进程开始满足不了各个应用程序的需求,于是出现了多线程,多线程仅仅是多进程的进一步细化,操作系统依然是以进程为单位分配资源,同一个进程中的多个线程共享一个进程的资源。多线程的设计延续了多进程的经验,依然是以时间片为单位进行抢夺式调度。流程如下:
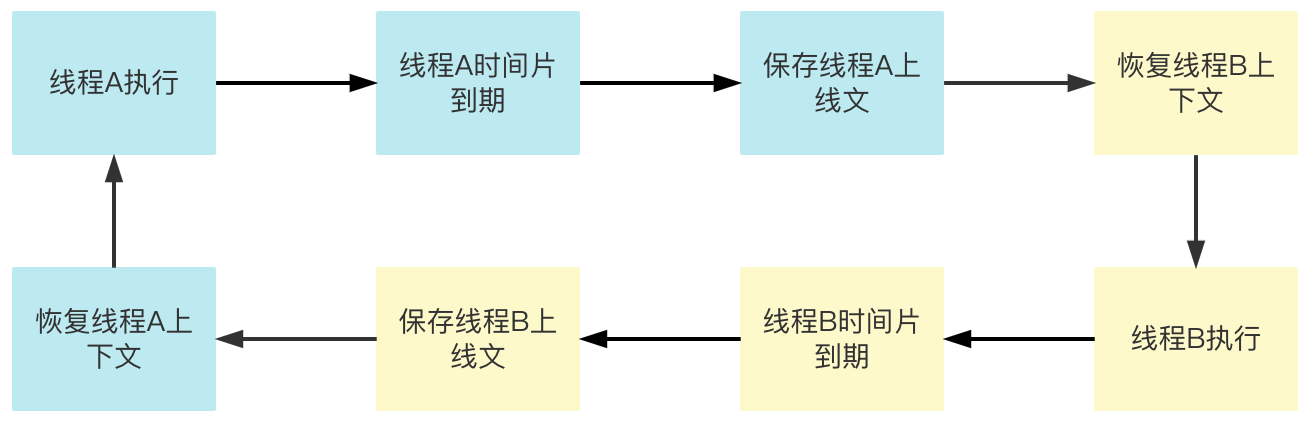
观察上面的流程图可以发现,一个进程中为了执行func A()和func B(),有可能多次经历:执行->休眠->执行的循环,也就是上下文切换。这种切换还涉及到用户态和内核态的状态转换,开销不可忽略。而对于A、B来说,不外乎三种情况:
A()、B()不存在数据依赖:也就是A、B之间相互独立,谁先执行也没有关系。A()、B()存在数据依赖:也就是B需要等待A执行的结果A()、B()可能存在系统调用导致阻塞,比如常见的IO,但是这种情况和情况二归为一类。
对于第一种情况就很简单了,CPU就顺序执行A()、B()即可,如下图。

对于第二种情况,有两种方案,第一种方案是在程序中指定A、B执行的顺序,但是这种方案比较复杂,毕竟一个庞大的程序的依赖逻辑是比较复杂的。第二种方案便是提供一个协程间协作的方式,例如A()执行完毕之后可以通过某个信号量通知B(),B()在收到信号之后才开始进入协程调度。
熟悉golang的同学在这里应该可以看出来,在golang中,这个协程间通信方式就是
channel
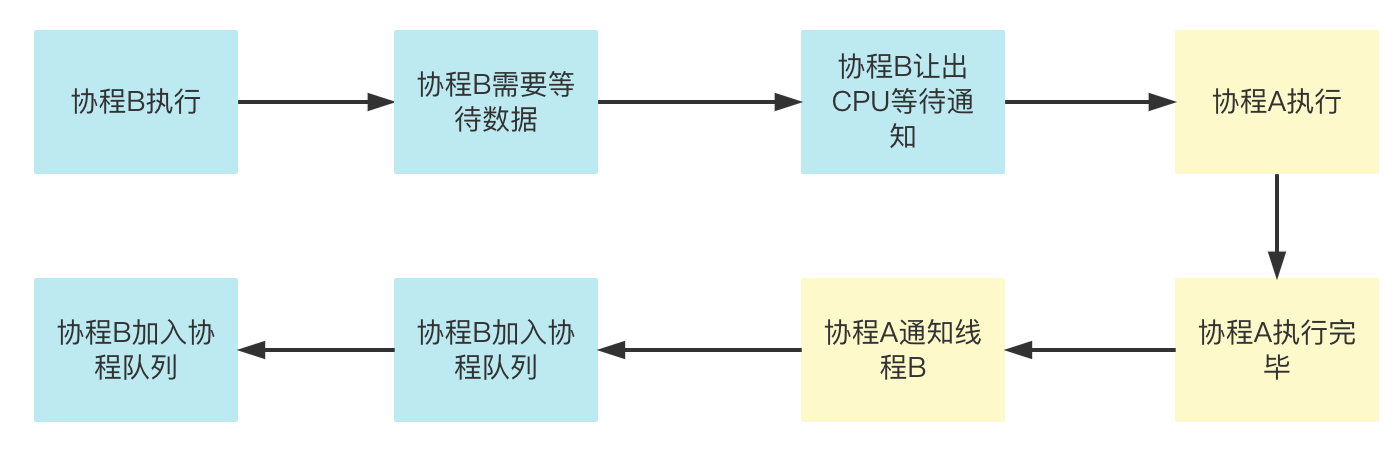
但是,回想多进程为什么会从协作式任务切换为抢占式任务?是为了防止有进程恶意霸占CPU不释放,而导致系统瘫痪。但是对于线程来说,同一个系统的开发者都是可控的,因此对于同一个进程中的多任务采用协作的方式也是可行的。
Go 协程
理解了协程的由来,再来看看Goroutine的实现。
在Go中,Go为协程提供了gouroutine和Channel,goroutine是对协程的抽象,而channel是提供协程间通信的通道。相对于线程来说goroutine非常轻量,一个goroutine仅占2KB,同时可以动态扩容和缩容。
一般来说,Go在启动的时候,会启动GOMAXPROCS 个线程,用来轮流调取协程。
在Go调度模型中:
G(Goroutine coroutines)是对协程的抽象M(Machine Kernel level threads)是对操作系统线程的抽象P(Processor Resources required for collaborative process operation):位于G和M之间,主要用于保存G队列
一般来说,协程的实现只需要内核线程+协程即可,这也是最开始Go1.1版本之前的实现,如图所示:
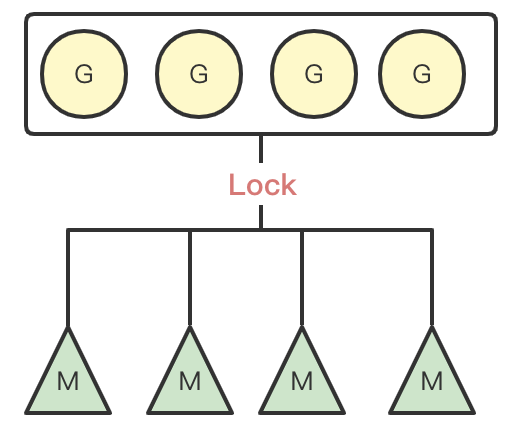
但是以上模型存在一个问题在于由于所有的M都共享一个全局G队列,因此每次M在获取G时都需要加锁;同时,从局部性原理来说,对于一个G,其创建的子协程由于具有数据相关性,因此最好使用同一个M进行调度。单存的GM模型,无法解决以上问题。
GMP借鉴了ThreadLocal原理,在GM模型的基础上添加了一层P,P作为G与M的中间层,每个P都只会绑定到一个活跃的M,每个M都会优先从本地P获取G,本地P中没有G时才会去全局队列获取其他P队列获取G, 通过中间层P,在大幅度减少锁的争用的同时,还最大程度的利用了局部性原理:
GMP之间的关系如图:
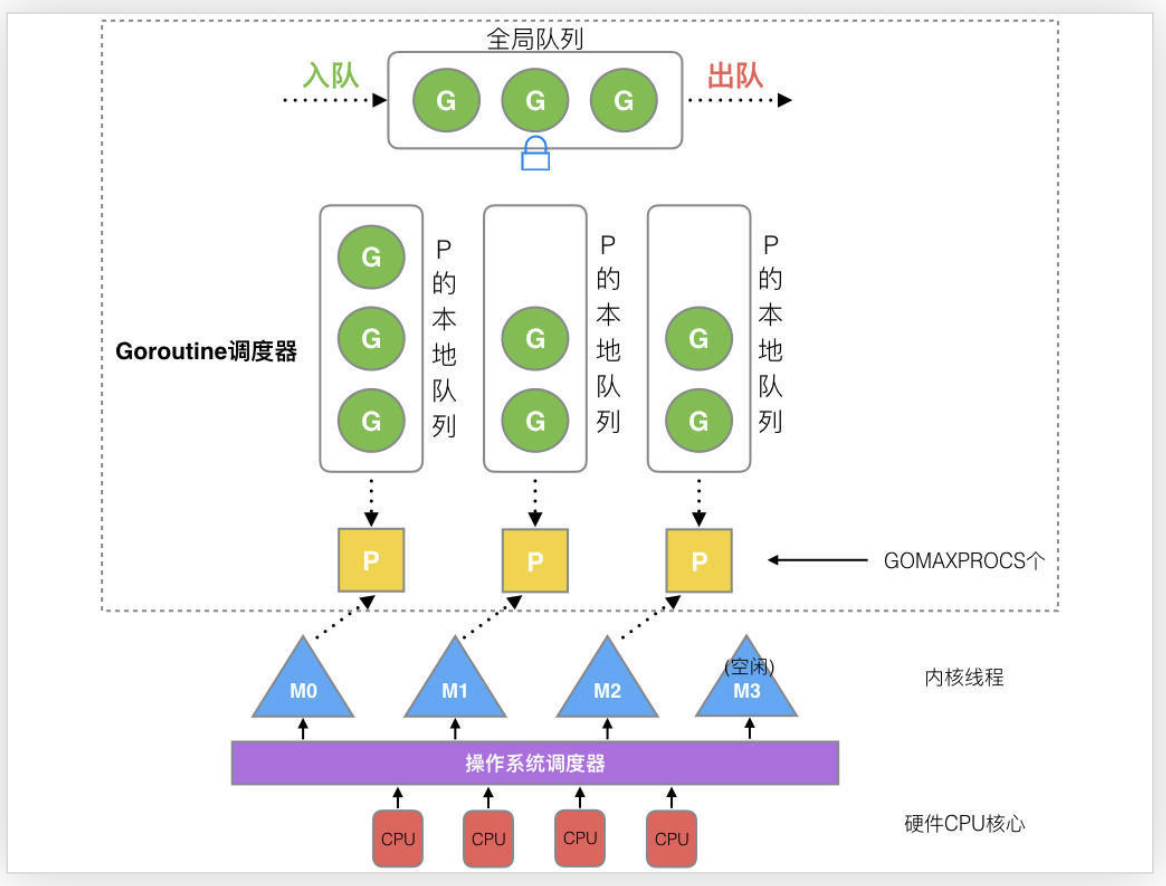
图片来源:https://learnku.com/articles/41728
协程的调度
G便是go语言提供的协程(goroutine),通过go关键字创建,协程创建后不会理解被执行,而是会存放在调度队列中,go提供了两个调度队列,P的本地队列和全局队列,当P的本地队列满了之后,新创建的goroutine则会被存放在全局队列中。
当G在执行时会出现以下三种情况:
- 正常顺利执行完毕
- 当前
G的执行需要依赖其他G产生的数据 - 当前
G需要执行系统调用导致阻塞
对于情况一:M只需要按顺序执行指令即可。
对于情况二:Go提供了channel来实现协程间的协作:典型代码模板如下:
func producer(c chan<- int) {
for {
time.Sleep(1 * time.Second)
c <- 1
}
}
func consumer(c <-chan int) {
for {
fmt.Println(<-c)
}
}
func TestChannel(t *testing.T) {
c := make(chan int, 10)
go producer(c)
go consumer(c)
select {}
}
对于consumer()函数来说,如果其依赖的数据为准备完毕,对应的流程如下:
- 通过
go关键字创建goroutine,加入本地或全局G队列 G成功绑定到M,并开始执行consumer()consumer从channel中获取数据,但是channel中并没有准备好的数据channel执行gopark(),将当前G从M中解绑,M继续调度其他G
此时,对于producer()函数来说,其对应的流程如下:
- 通过
go关键字创建goroutine,加入本地或全局G队列 G成功绑定到M,并开始执行producer()producer初始化局部变量1,并将其发送给channelchannel接受到数据,并发现有等待唤醒的consumer()协程在等待数据channel执行goready(),将consumer()协程重新加入队列中consumer()成功绑定M,继续执行下一步。
可以看到,对于存在协程间数据依赖的情况,可以通过channel来完成协程的间的数据传送。
对于情况三:
当G执行了syscall或则其他导致阻塞的操作时,M也会被阻塞,此时runtime会把这个被阻塞的M从P中摘除,然后在尝试唤醒一个休眠的M或者创建一个新的M来绑定到P中。
当阻塞结束时,这个G会尝试获取一个空闲的P再次绑定到M中,如果绑定成功,则G会加入到P的空闲队列等待执行,如果没有找到空闲的P,那么这个M会变成休眠状态等待复用,而这个G则会被加入到全局队列中等待被执行。
协程与IO阻塞
从go对协程的调度可以看出来,当协程执行系统操作阻塞导致M也阻塞的时候,Go会重新启动一个新的M来保证协程的调度不被影响。这会带来一个新的问题:网络IO。
我们知道在传统的网络`IO中,由于无法知道对端的数据何时才能准备完毕,因此在等待数据或链接的时候,都需要阻塞。
l,err:=net.Listen("tcp","0.0.0.0:8080")
for{
//阻塞
conn,err:=l.Accept()
//阻塞
conn.Read()
}
从上面代码可以看到,在等待连接的时候需要阻塞,而对于每条链接等待对端发送数据的时候,也需要阻塞。
而按照上面所描述的go处理协程系统调用导致阻塞的时候,协程会导致M也阻塞,进一步会使得系统再新启动一个M,如果这个系统是一个Web系统,也就是大多数线程都是用于处理IO,那么相当于协程便退化成了线程。因为此时相当于每个协程占用一个线程,协程与线程形成了1:1的关系。我们知道对于操作级别的线程,每个线程至少需要占用2M的内存,同时操作系统的线程过多会导致系统上下文争用过大,引起额外开销。这相当于go协程所做的努力在Web系统中完全无效。
因此,go重构了所有的net库,通过epoll多路复用以及非阻塞的特点,使得协程在执行网络IO需要阻塞时,可以通过释放M从而达到阻塞效果,当协程中的连接有数据可读时,runtime负责唤醒协程:
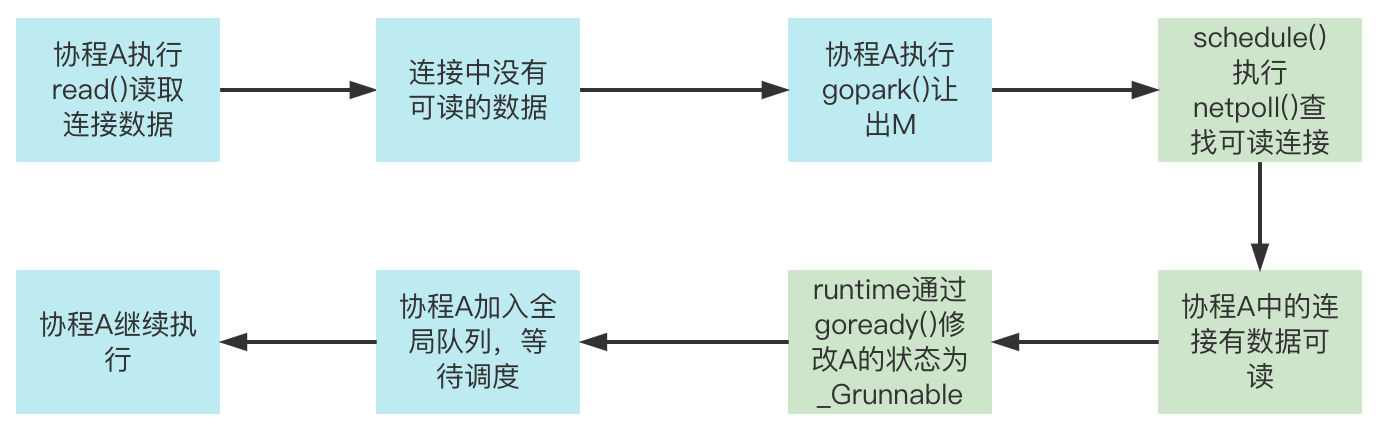
通过这种方式,使得所有的协程在执行网络IO时,不再退化为线程,极大的提高了系统的性能。
总结
刚接触到Go语言时,印象最深的便是协程和net库默认使用epoll以及channel的协程协作。但是细细梳理下来可以发现,这些都是实现协程必然的前提条件。然而对于Go来说,由于一些Bug(https://github.com/golang/go/issues/543),Go在1.14版本将goroutine从协作式协程修改为了抢占式协程。感兴趣的同学可以分别在Go1.13版本和Go1.14版本执行下面的代码,观察程序退出时间的差别:
func TestGoroutine(t *testing.T) {
runtime.GOMAXPROCS(1)
go func() {
for {
fmt.Println(1)
}
}()
//等待goroutine完全启动
time.Sleep(10 * time.Millisecond)
fmt.Println(2)
return
}