LFU 缓存实现
最近在复习Redis缓存策略的时候,看到Redis 4.0支持了一种新的缓存淘汰策略:LFU(Least Frequently Used),猛然想起在Dubbo的介绍中,也说过这个策略。
LFU主要是淘汰最近使用次数最少的元素,当使用次数相同时,再使用LRU策略进行淘汰。
引用Redis作者的介绍,LFU策略主要用来解决以下问题:
~~~~~A~~~~~A~~~~~A~~~~A~~~~~A~~~~~A~~| ~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~| ~~~~~~~~~~C~~~~~~~~~C~~~~~~~~~C~~~~~C| ~~~~~D~~~~~~~~~~D~~~~~~~~~D~~~~~~~~~D|
如图,如果缓存容量为3,那么如果使用LRU策略则在插入D之后,下一个需要淘汰的则是A,但是从上面的图可以看出来,A使用的频率是比较高的。
那么应该如何自己实现一个LFU缓存呢?
参考LRU的实现方式,我们依然可以通过一个HashMap来维护K和V的关系,然后单独维护一个列表来按照访问的次数进行排序。
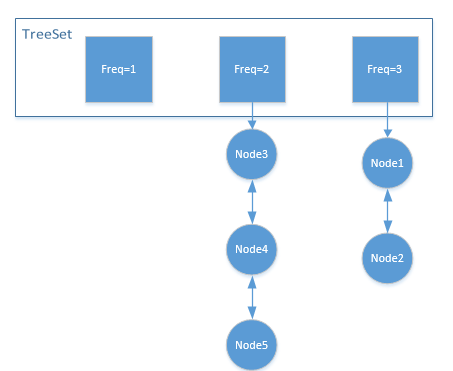
列表,排序,两个关键词放一起很容易想到,TreeSet:
TreeSet中存放的是一个个双向链表,用来实现LRU策略。
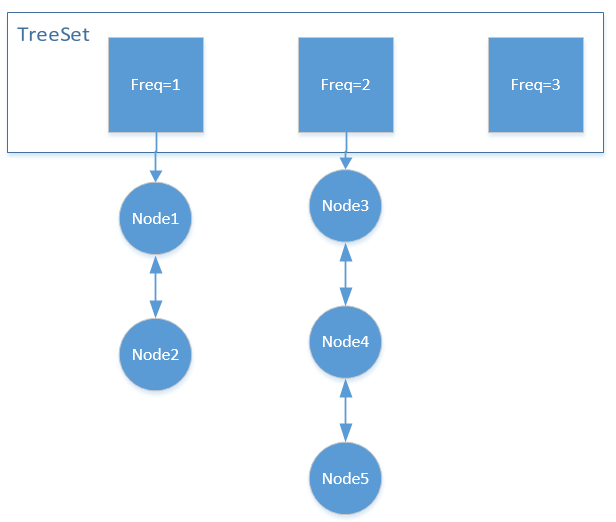
如图所示,每次需要淘汰的时候,主要获取TreeSet中元素最小的链表的尾元素进行删除即可。
Node结构伪代码如下:
{
//对应的Key
K key;
//对应的value
V value;
//访问的次数
int freq;
}
get/set 尾代码如下:
V get(K key){
//通过map获取元素Node
//如果Node存在,则获取此元素的访问次数freq
//将此Node的freq++,然后更新其在TreeSet中的位置
}
void put(K key,V value){
//如果元素存在,则增加其freq,操作同get
//如果元素不存在,且当前缓存容量已满,则TreeSet中元素最小的链表的尾元素,将其删除
//new Node,令Freq=1,将其插入TreeSet和Map中
}
如此来看,LFU便成功实现,但是时间复杂度呢?
我们一共使用了两种数据结构,Map和TreeSet,Map的时间复杂度是O(1),但是TreeSet的时间复杂度是O(logn),如果Redis真的也使用这种方式来实现的话,那也太影响性能了,每个get\set都变为了O(logn)。
有没有更好的实现方式呢?
仔细看上面的代码,我们可以发现,我们使用TreeSet是为了维护freq大小顺序,但是freq的大小顺序并不是无序变化的,每访问一次,就加一。当需要淘汰的时候,就淘汰最小的freq.我们有没有办法将维护freq大小的数据结构,也变成Map呢?
简单分析一下就可以看出来,我们同样可以使用一个Map<Integer,Node>来保存freq队列,当get()元素的时候,通过Map获取元素,然后将feq++,放入另外一个队列。当put()元素的时候,删除最小的freq队列的尾元素即可。
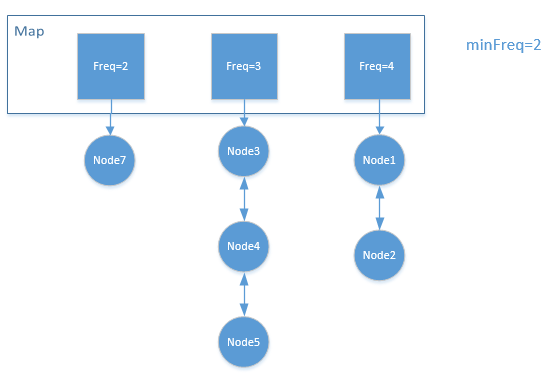
最小?我们怎么知道当前freq最小是多少呢?我们可以通过minFreq来记录,每次get(),put()的时候更新即可。
这里巧就巧在,可能有人会问,比如当前最小
freq=3,当我缓存满时候,正好将这个元素淘汰了,那我怎么知道下一个最小的freq等于多少呢?仔细分析下就可以知道,当需要使用
minFreq的时候,一定是在put()的时候,发现缓存容量已满,需要先淘汰一个元素,而当调用put()需要被删除的时候,那么此时由于会插入一个新的元素,这个元素的freq则等于1,它便是minFreq。
get()操作,将Node7的freq++,发现freq=3,于是移动到Node3前面,此时freq=2中的元素为空,因此minFreq=3put()操作,如果缓存容量没有满,则新建Node,令freq=1,此时minFrq=1put()操作,如果缓存容量已满,则需要淘汰元素你,通过minFrq定位到队列,淘汰其尾元素,然后插入新的元素,此时minFrq=1
要是能明白上面的道理,写起代码来就很简单了。
明白的同学可以去LeetCode上尝试一下。
容易写出Bug的地方:
- 最开始我翻看
Dubbo(V2.7.7)的LFUCache的实现,路径如下:org.apache.dubbo.common.utils.LFUCache发现其没有维护minFreq,而是通过一个数组frq_Table来代替了HashMap,默认刚添加的元素放在table[0]中,每访问一次,就将其index+1,有点类似于桶排序的原理,利用index来进行排序。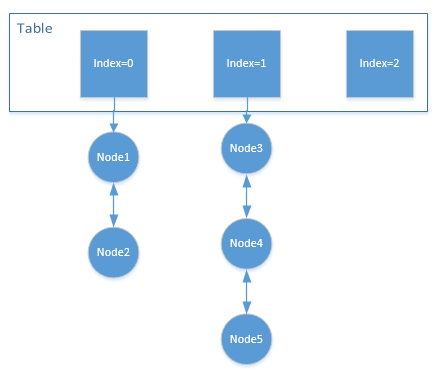
如图,当需要淘汰元素的时候,就通过遍历数组,找到第一个不为空的列表,删除其尾元素。
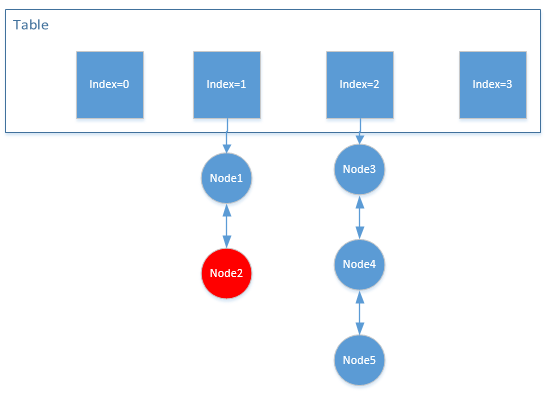
如上图,当需要淘汰的时候,会找到
index=1中元素不为空,然后删除尾元素node2这就是它的核心思想,但在我多次推敲其代码实现之后,发现这样做存在一个问题,那就是数组的容量是有限的。
Duboo初始化数组的大小为capacity+1this.freqTable = new CacheDeque[capacity + 1];这样实现的话,当你对其中的元素进行反复
get()(次数大于capacity),则它将退化成一个LRU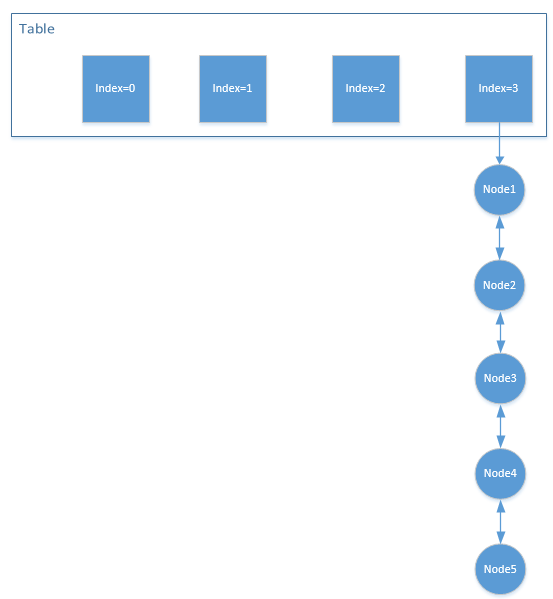
因此
Dubbo的实现方案,估计需要从新推敲。 -
在编写代码的时候,调用
put()方法的时候,有两种方式。
-
第一种,先判断缓存容量,如果容量已满则淘汰元素,然后插入新的元素
-
第二种,先插入新的元素,然后再判断容量,如果容量已满则淘汰元素。
简单想一想看起来其实差不多,无非就是新的元素会不会参与淘汰的比较,但是如果采用后者,则又会出现一个
bug,那就是这个缓存无法进行缓存。比如,目前缓存的情况如下图所示:
也就是
freq=1的位置为空,此时插入新的元素将会放入freq=1的位置,然后发现容量已经满了,需要淘汰元素,此时查找会发现访问最少的元素就是刚刚插入的元素,又会将其删除。也就是说,这个缓存,将永远无法插入新的元素,因为刚插入的元素就会马上被淘汰,因此需要先淘汰其他元素,再进行插入。Dubbo的LFU就是采用的后者,这也是一个bug
- 在做
LeetCode上的LFU的时候,想偷懒就是用了LinkedList来实现LRU,做完后才发现怎么时间才超过20%的人,仔细想才发现,由于LinkedList中的Node和LFU中的Node不是共用的,因此在淘汰的时候,需要将Node从LinkedList中删除的时候,这个remove()操作时间复杂度是O(n),需要遍历对比,因此最好还是自己实现LRU,才能保证真正的O(n)